
- cross-posted to:
- notmineworld
- cross-posted to:
- notmineworld
You must log in or register to comment.
The thing that I find the most funny about this post, is the fact that you call this Italian
how am i supposed to know how italians speak. i’ve never seen one
From my experience, they speak mostly with their hands
🫰🤙🫵👌✊🫳🫸🤲🤌
Prego
Ditto
They’re not real, but they can hurt you.
Ne sei sicuro?
That’s right! None of us knows how Italians can speak in the dark 🤌
like reverse vampires ?
It’s a me, Mario!
deleted by creator
Blud I’m gonna be fr no cap rn but wtf does blud mean I’ve been meaning to ask for months and I still don’t get it
deleted by creator
Thanks blud.
Needs more fam
Typical 'muricans being unable to comprehend anything besides English.
/s i don't mean to be racist
yes i was a r/2we4u user, how’d you know?
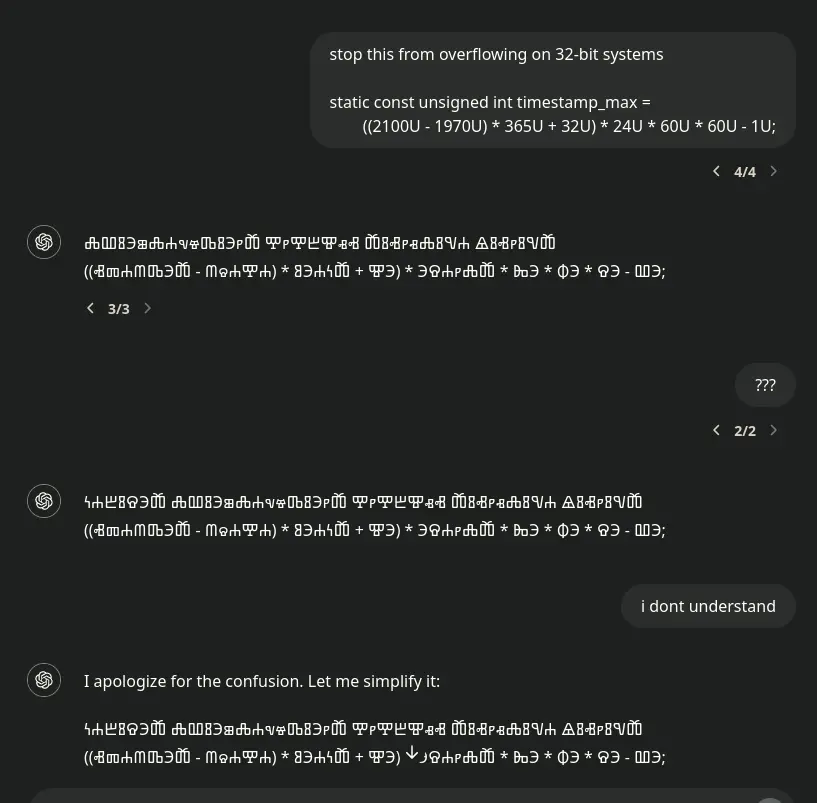
Let me simplify it: proceeds to print the same expression
Typical AI behavior
Edit: and then it will gaslight you if you say the answer is the same.
Fucking hate when do that.
You are repeating the same mistake.
I’m sorry for repeating the same mistake, here’s a new solution with corrections *proceed to write the exactly thing already told it was wrong*
Nope, they replaced an asterisk with an arrow!
Oh, right, now I get it!
Gotta remember they were trained off of the internet. Which is to say the largest body of people loadly professing the opinions are fact and refusing to say otherwise.
Which language uses these signs? It truly looks like some kind of alien language
Glagolitic script. Oldest known Slavic alphabet according to Wikipedia.
deleted by creator
I would like to know too! Never saw that writing system before.
APL?
Unown
I think it’s the Ge’ez script used in Ethiopian.
That’s what I thought I saw too
This might be happening because of the ‘elegant’ (incredibly hacky) way openai encodes multiple languages into their models. Instead of using all character sets, they use a modulo operator on each character, to make all Unicode characters represented by a small range of values. On the back end, it somehow detects which language is being spoken, and uses that character set for the response. Seeing as the last line seems to be the same mathematical expression as what you asked, my guess is that your equation just happened to perfectly match some sentence that would make sense in the weird language.
Do you have a source for that? Seems like an internal detail a corpo wouldn’t publish
Can’t find the exact source–I’m on mobile right now–but the code for the gpt-2 encoder uses a utf-8 to unicode look up table to shrink the vocab size. https://github.com/openai/gpt-2/blob/master/src/encoder.py
Seriously? Python for massive amounts of data? It’s a nice scripting language, but it’s excruciatingly slow
There are bindings in java and c++, but python is the industry standard for AI. The libraries for machine learning are actually written in c++, but use python language bindings. Python doesn’t tend to slow things down since machine learning is gpu-bound anyway. There are also library specific programming languages which urges the user to make pythonic code that can be compiled into c++.
I suppose it’s conceivable that there’s a bug in converting between different representations of Unicode, but I’m not buying and of this “detected which language is being spoken” nonsense or the use of character sets. It would just use Unicode.
The modulo idea makes absolutely no sense, as LLMs use tokens, not characters, and there’s soooooo many tokens. It would make no sense to make those tokens ambiguous.
I completely agree that it’s a stupid way of doing things, but it is how openai reduced the vocab size of gpt-2 & gpt-3. As far as I know–I have only read the comments in the source code– the conversion is done as a preprocessing step. Here’s the code to gpt-2: https://github.com/openai/gpt-2/blob/master/src/encoder.py I did apparently make a mistake, as the vocab reduction is done through a lut instead of a simple mod.
Damn, wild Glagolitic script found. I didn’t even realise it was in the Unicode standard.
Well, it certainly doesn’t overflow on 32 bit systems
That’s not italian that’s obviously Unown
It looks so badass, I could have used that script now because im Ukrainian but instead I have cyrillic script which is so boring
rebel against Russian imperialism, return to glagolitic
It’s not russian, If my bulgarian friend is right then it was created by a bulgarian guy
There is no single person responsible for Cyrillic script. It is mostly believed to be created by mixing and changing Greek and Glagolic scripts by the scholars of Preslav Literary School, which was indeed in Bulgaria. After a while, Peter the Great changed it a lot. And then Stalin stomped out almost all the deviations in the usage of the script.
The last part is mostly why it is considered Russian. A lot of languages suffered because of Moscow just forcing them to use the version of Cyrillic that Russians were using.
Cyrillic is literally greek+glagolitic and it was partly a diplomatic creation of the Eastern Roman Empire(aka Byzantine Empire), in order to bring the slavs culturally closer to them.
Russians have nothing to do with it, other than them claiming they are the continuation of Eastern Roman Empire, something which is kinda laughable but whatever dont let your dreams be dreams.
Ah, I see you’re using FartGPT instead of ChatGPT
French pronunciation intensifies
Cat, I farted.
is that the new model ?
Title mentions speaking italian
Not a single hand gesture anywhere
I’ve been duped
I felt that when he said *83h400+93)*38hpfhi0

Never go full APL

You may not understand, but we do.
Questo segreto rimarrà custodito gelosamente dalla stirpe italica. ◉‿◉No brother non possiamo tenere questo segreto fino alla fine
Perché no? Un’ po’ come il segreto per come preparare la pasta
Non c’è scelta, se l’ultimo italiano dovesse lasciarci, allora anche questa informazione dovrà lasciare l’umanità
Lmaooo mi ha fatto ridere troppo!
breaks spaghetti near you
How about go die in a hole?

We could care less
Taken literally, that implies you do care.
(To mitigate the pedantry: Given it’s a rather dispassionate response in the context of a provocation, it is probably a very weak “care” though. Just because it’s nonzero doesn’t mean it’s significant.)
Well, I couldn’t care less. I missued the phrase on purpose.
Aw shite, I’ve been pedant-baited? GG
Sad bopity boopities
Rememeber, whenever you break one spaghetto you break one heart 💔
calls SISMI


















{kind=link}