

{kind=link}
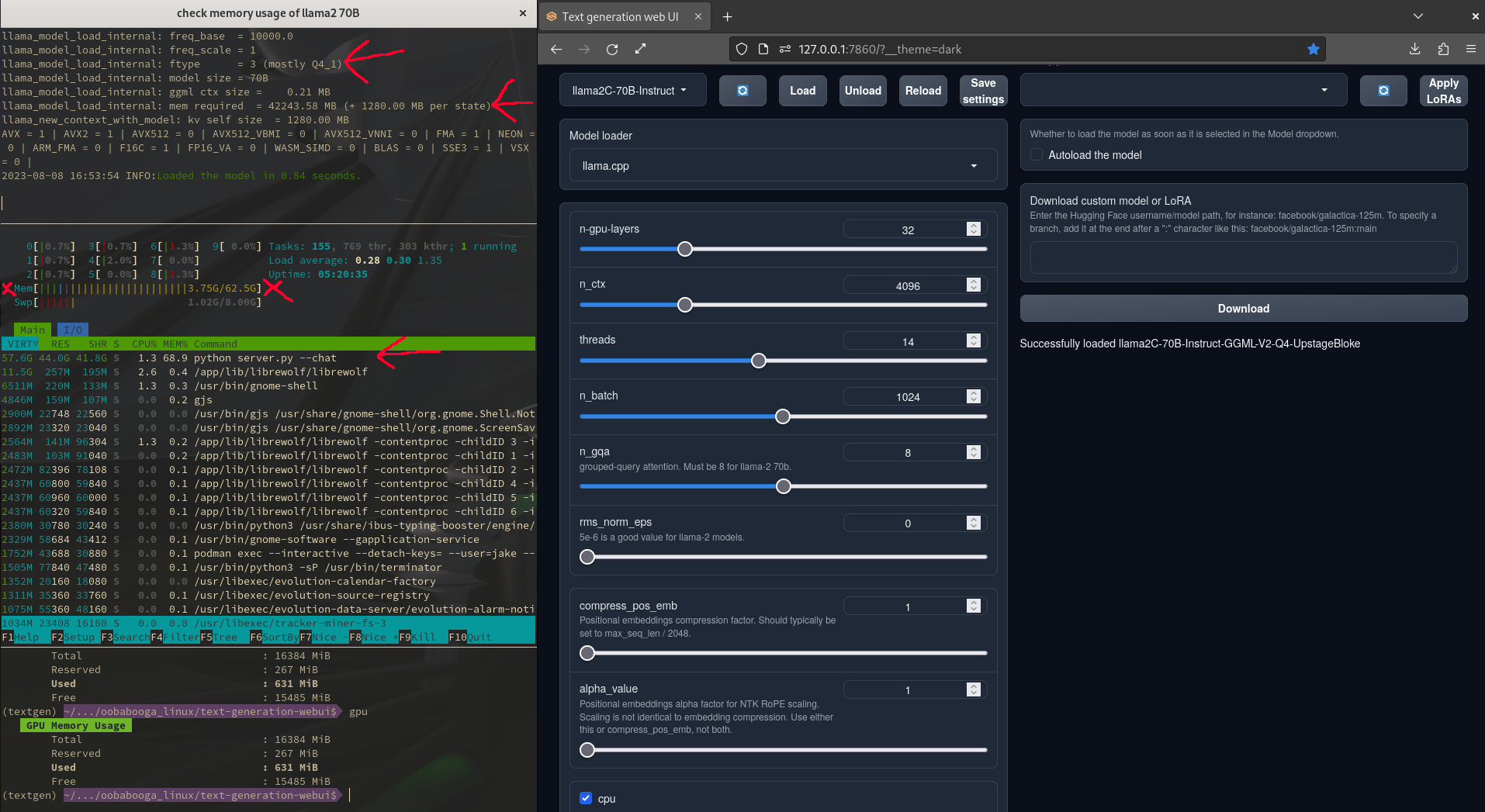
Follow the red marks in the main picture. HTOP is not showing the distrobox container’s memory usage in the bar graph, but it does display the correct memory usage in the processes window. The top left terminal shows the tty that launched Oobabooga. The bottom terminal is just a bash function I wrote to quickly check GPU memory usage and has no import here. What it shows is just the desktop environment.
One note: I left the GPU layers as I normally set them, (as pictured in the image), but there is no hybrid support with the llama.cpp file and this 70B GGML in Oobabooga.
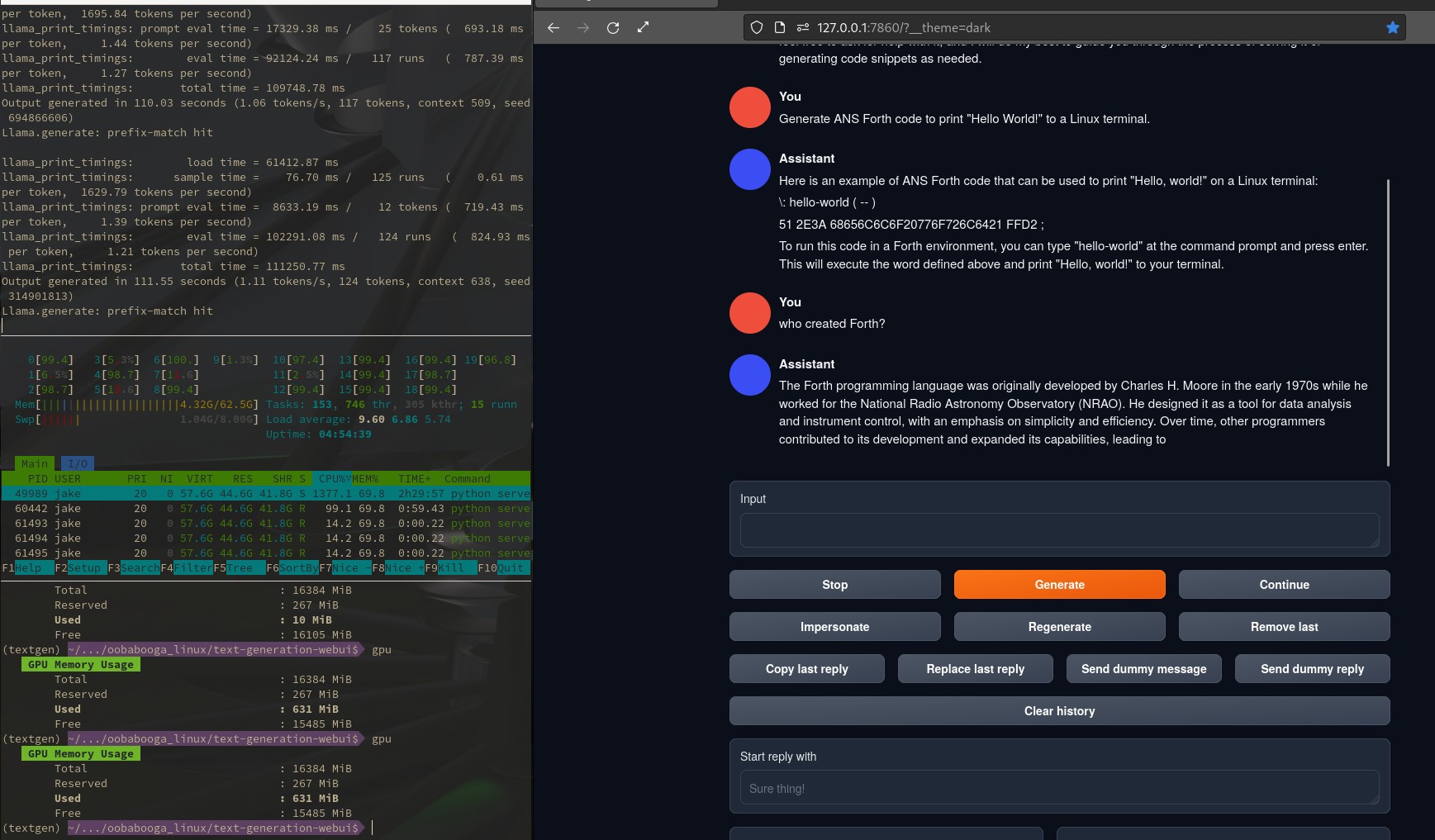
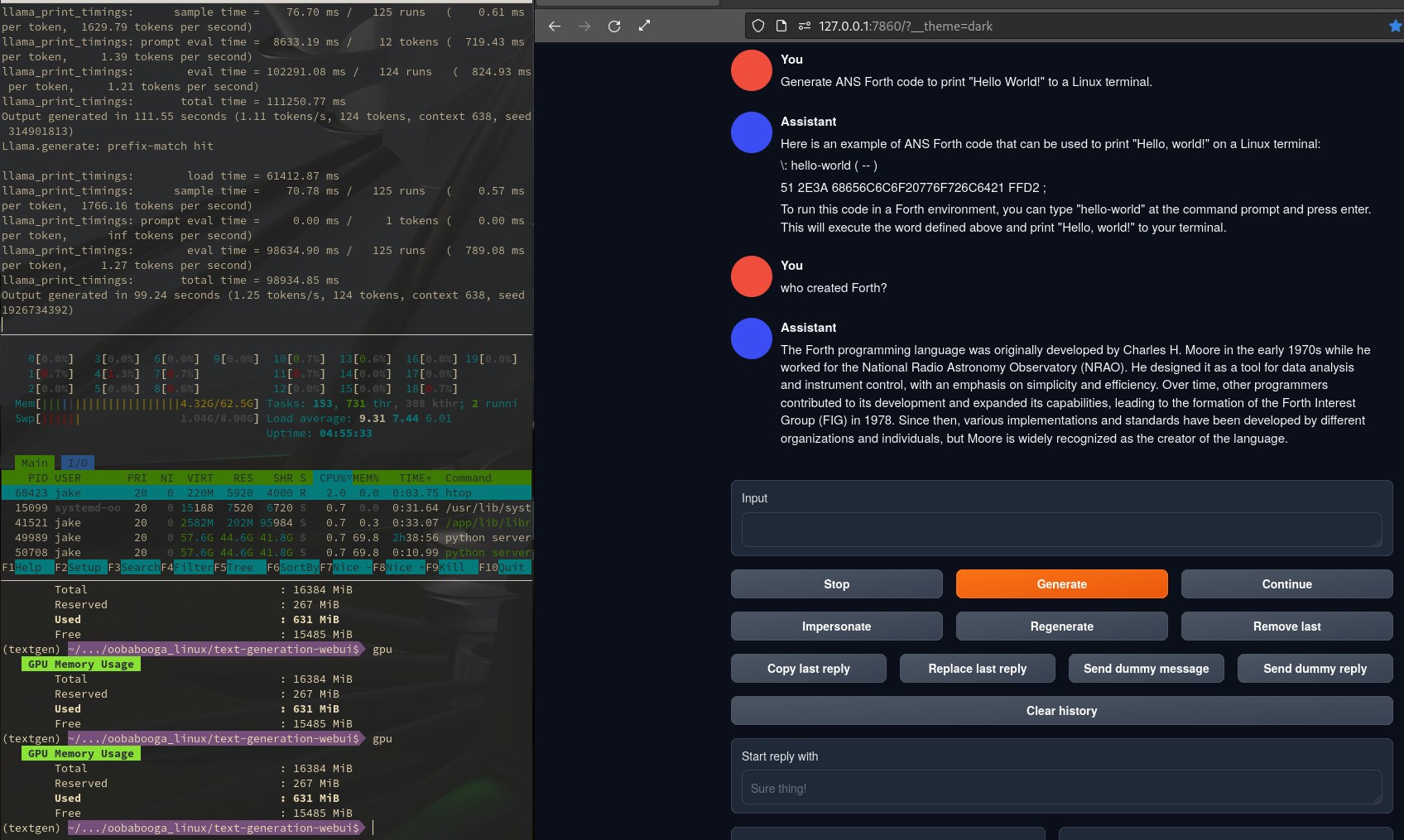
If you are ancient like me, and remember things like AOL instant messenger on 56k dialup, that is about what this feels like. Below there are two images. One shows an output as it is generating, and the other shows the results at the end of generation. That block of text took just over a minute and a half to complete just like it says.
The Forth code is not right, but overall the outputs here are far better than any other models I have tried thus far. Most can’t even correctly identify the creator of Forth and if told they will head off on a hallucinogenic trip. As far as I know, no model is trained on Forth. This is a basic Wikipedia facts test, and an exercise in how boldly a model will lie about code it has no training on. As an aside, this model managed to get several elements of Forth correct, which is quite impressive for no training.
This is really interesting, thanks for sharing!
For our hardware heads, do you think you could share a spec sheet of your device?
Love seeing 70B parameter models being ran at home! Imagine where we’ll be a year from now…
It is an enthusiast level machine. A Gigabyte Aorus YE5. It is not a great choice for a Linux machine, but I don’t know if any of the other 2022 machines that came with a RTX3080Ti are any better. There are some settings that can not be changed except through Windows 11 due to proprietary software for peripherals like the RGB keyboard. Nothing too bad or deal breaking. Basically it is a twelfth gen Intel i7 running somewhere around 4.4-4.7GHz under boost. The machine has 20 logical cores total. The demo I shared put the LLM on 14 logical cores. I’ve also upgraded the system RAM to the maximum of 64GB. This is the only reason I am able to run this model. It pushes right up against the maximum available memory. In fact it also pushes into the 8GB swap partition from the NVME drive when the model is first loaded. I haven’t looked into this aspect in detail. Loading is very fast. I’m simply looking at the amount of virtual memory against that of other running processes on the host and distrobox. It is probably not wise to do much in the background while this thing is running. I haven’t tested it long enough to max out the context or anything. I’ll report back if there are major issues though. Maybe one day this will have hybrid support where I can offload some layers on my GPU.
The main hurtle I had with getting this running was conda not installing correctly for some reason. I’m not sure what happened with that one. I think the version that actually installed Oobabooga was on the base host somehow. Anyways it left me with some conflicting dependencies that still ran Oobabooga but kept some aspects of the software from updating correctly. I think this is why I had so much trouble with Bark TTS too.