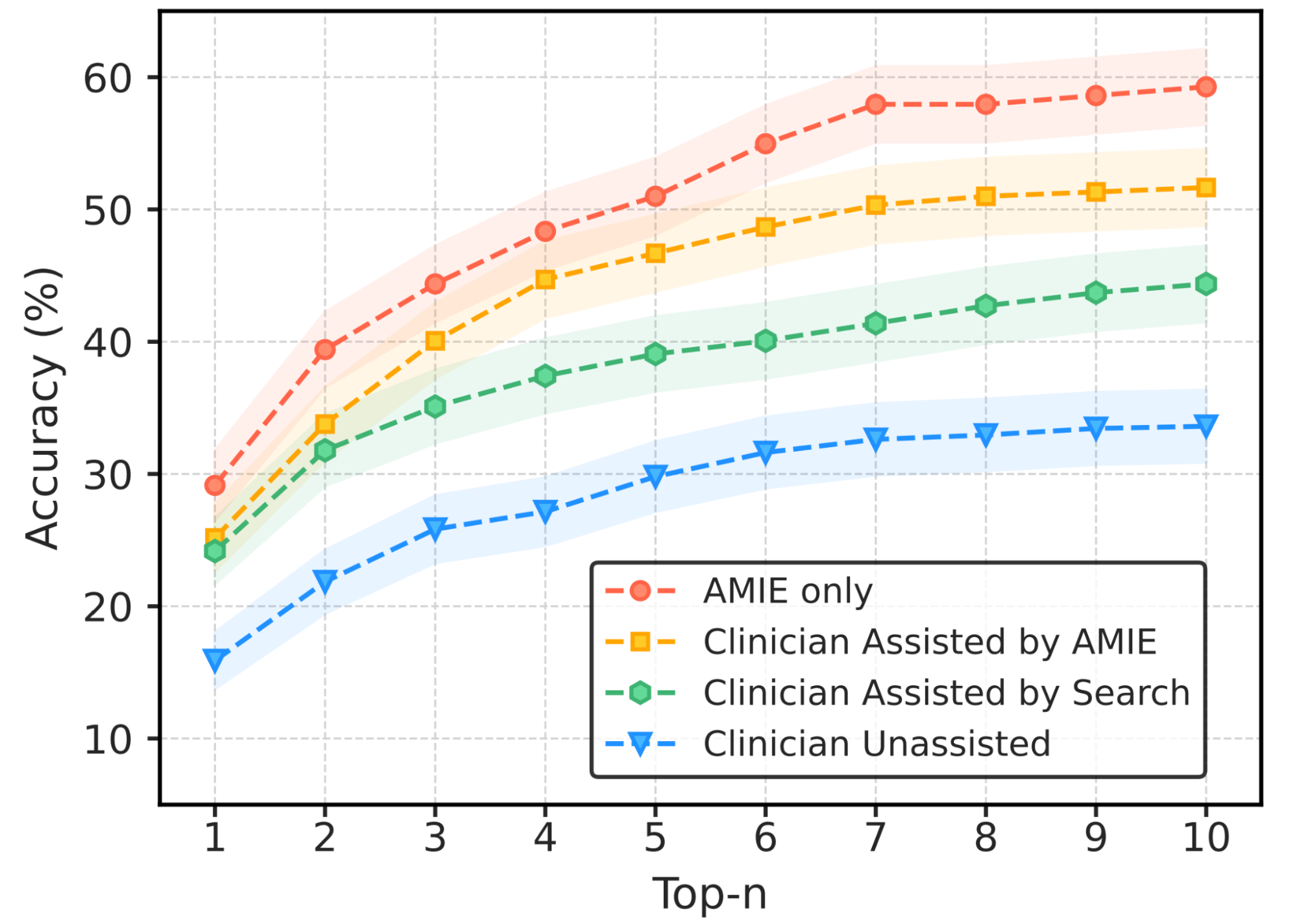
So there were two different configurations the model was evaluated against.
One was where they simulated patients and had them interact in an LLM like environment. In this one the model and real physicians were evaluated using an evaluation method called OSCE.
The other was having the model and physicians diagnosis old cases pulled from journals.
While the models arguably perform better in these environments, I don’t think anyone would consider these real world situations/environments. It seems closer to “LLMs being able to pass the bar” than “LLMs have been able to pratcie law”, as we’ve seen the former, but have not seen the latter.

{kind=link}
I only skimmed the article, do these results rely on the patient giving informative answers that are easily parsed by the AI?
For example “my arm hurts” might give a different diagnosis than “my shoulder and upper biceps are swolen after my workout an hour ago”
So there were two different configurations the model was evaluated against.
One was where they simulated patients and had them interact in an LLM like environment. In this one the model and real physicians were evaluated using an evaluation method called OSCE.
The other was having the model and physicians diagnosis old cases pulled from journals.
While the models arguably perform better in these environments, I don’t think anyone would consider these real world situations/environments. It seems closer to “LLMs being able to pass the bar” than “LLMs have been able to pratcie law”, as we’ve seen the former, but have not seen the latter.
Additionally, Google will be on my “approach with caution” list for a while after the gemini fiasco - https://arstechnica.com/information-technology/2023/12/google-admits-it-fudged-a-gemini-ai-demo-video-which-critics-say-misled-viewers/