

Relevant section explaining the solution:
Let’s return to Hamlet, but this time your working memory — consisting of a whiteboard — has room for just 100 words. Once the play starts, you write down the first 100 words you hear, again skipping any repeats. When the space is full, press pause and flip a coin for each word. Heads, and the word stays on the list; tails, and you delete it. After this preliminary round, you’ll have about 50 distinct words left.
Now you move forward with what the team calls Round 1. Keep going through Hamlet, adding new words as you go. If you come to a word that’s already on your list, flip a coin again. If it’s tails, delete the word; heads, and the word stays on the list. Proceed in this fashion until you have 100 words on the whiteboard. Then randomly delete about half again, based on the outcome of 100 coin tosses. That concludes Round 1.
Next, move to Round 2. Continue as in Round 1, only now we’ll make it harder to keep a word. When you come to a repeated word, flip the coin again. Tails, and you delete it, as before. But if it comes up heads, you’ll flip the coin a second time. Only keep the word if you get a second heads. Once you fill up the board, the round ends with another purge of about half the words, based on 100 coin tosses.
In the third round, you’ll need three heads in a row to keep a word. In the fourth round you’ll need four heads in a row. And so on.
Eventually, in the kth round, you’ll reach the end of Hamlet. The point of the exercise has been to ensure that every word, by virtue of the random selections you’ve made, has the same probability of being there: 1/2^k. If, for instance, you have 61 words on your list at the conclusion of Hamlet, and the process took six rounds, you can divide 61 by the probability, 1/2^6, to estimate the number of distinct words — which comes out to 3,904 in this case. (It’s easy to see how this procedure works: Suppose you start with 100 coins and flip each one individually, keeping only those that come up heads. You’ll end up with close to 50 coins, and if someone divides that number by the probability, ½, they can guess that there were about 100 coins originally.)
Chakraborty, Variyam and Meel mathematically proved that the accuracy of this technique scales with the size of the memory. Hamlet has exactly 3,967 unique words. (They counted.) In experiments using a memory of 100 words, the average estimate after five runs was 3,955 words. With a memory of 1,000 words, the average improved to 3,964. “Of course,” Variyam said, “if the [memory] is so big that it fits all the words, then we can get 100% accuracy.”
Randomization scares me a bit, but one can run several copies at the same time to get a better estimate, I guess. I like how you can easily obtain the granularity of an estimate after stopping, 2k is increment size after kth round.
I wonder, what are error distributions and how probable it is to not exceed 2k of an error, maybe I should read the article, after all 😅
Thank you for an excerpt
Edit: looks like if we have (ε, δ)-approximation if distribution of data, error would be less than δ/4
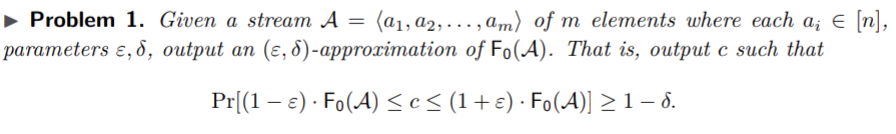
Wow this is surprisingly simple.
It really is. It’d make a wonderful assignment in a second level programming class.
We use hyperlloglog++ for this because it’s mergable across nodes and threads. I haven’t thought much about combining this one.
In a recent paper, computer scientists have described a new way to approximate the number of distinct entries in a long list, a method that requires remembering only a small number of entries. The algorithm will work for any list where the items come in one at a time — think words in a speech, goods on a conveyor belt or cars on the interstate.
The CVM algorithm … is a significant step toward solving what’s called the distinct elements problem, which computer scientists have grappled with for more than 40 years. It asks for a way to efficiently monitor a stream of elements — the total number of which may exceed available memory — and then estimate the number of unique elements.
“The new algorithm is astonishingly simple and easy to implement,” said Andrew McGregor of the University of Massachusetts, Amherst. “I wouldn’t be surprised if this became the default way the distinct elements problem is approached in practice.”
deleted by creator
So this is probably useful for statistics collectors in DBMSes, used for planning queries. Any other use cases jump to mind?
I thought it sounded kind of similar to statistical CPU profiling, where you’re sampling the program counter of a given thread to see which functions actually use the most time. Maybe this idea could help increase the sample rate.
Reminds me of reservoir sampling.

