
![[T2i][Tool] [Request] CLIP Interrogator - create prompt from an image](https://lemmy.world/pictrs/image/01d3b886-52c4-4843-9fdb-d103a95c4047.jpeg){kind=link}
Feed it an image, get the closest matching prompt out of a set of written alternatives.
Try it here: https://huggingface.co/spaces/pharmapsychotic/CLIP-Interrogator
Example
Input image from google

Result when running the output prompt on perchance text-to-image model

Source code for this version : https://github.com/pharmapsychotic/clip-interrogator
In this source code, here are the list of pre-made “prompt fragments” this module can spit out:
You can write any prompt fragments in a list, and the output will be the “closest matching result”.
There are other online variants that use CLIP , but sample a different prompt library to find the “closest match” : https://imagetoprompt.com/tools/i2p
The difference between these two is just what “pre-written prompt fragments” they have choosen to match with the image. Both use the CLIP model.
What is it?
The CLIP model a part of the Stable Diffusion model , but it is a “standalone” thing that can be used for other stuff than just image generation
It would be nice to have the CLIP model available as a standalone thing on perchance.
The CLIP model : https://github.com/openai/CLIP/blob/main/CLIP.png
{kind=link}
Practical use cases
Making for example a “fantasy character” image-to-prompt generator (note the order) by feeding it “fantasy prompt fragments” to match with
How does this work?
The CLIP model is where the “magic” happens.
Image below describes how CLIP is trained. It matches words with images in this kind-of-grid style format
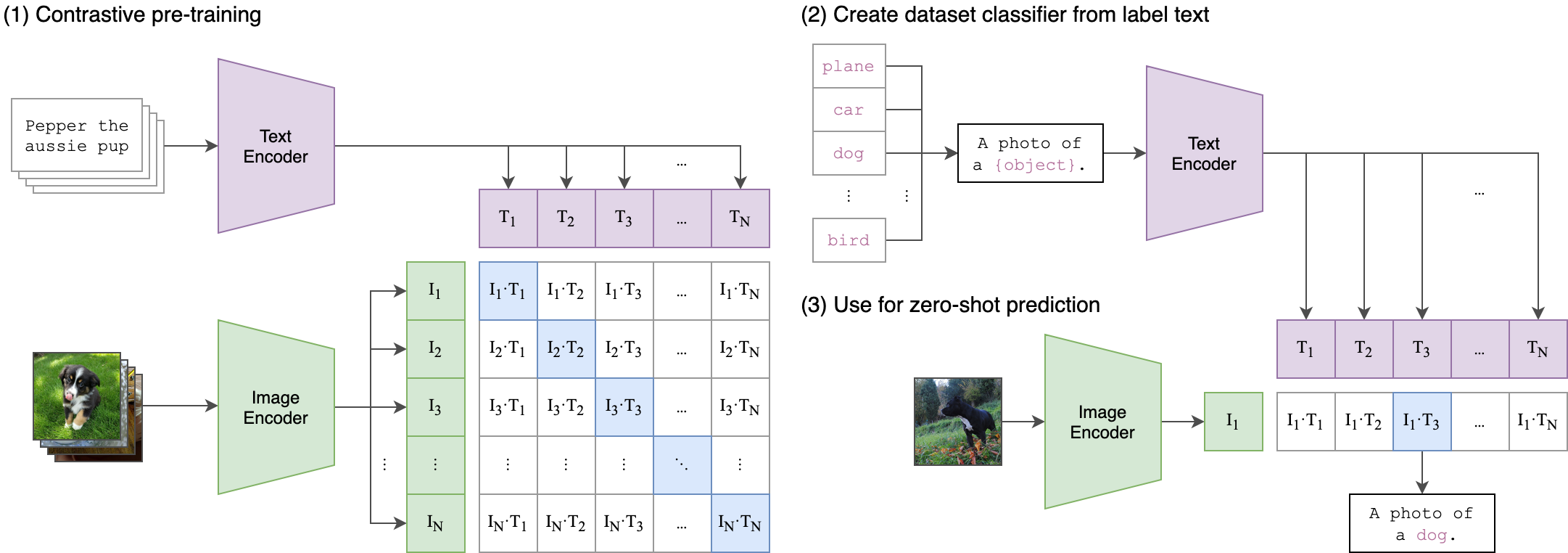
The CLIP model can process an image , or a text , and both will generate a 1x768 vector that are “the same” .
That’s the “magic”.
How to make your own purpose-built CLIP interrogator on perchance (assuming this is a feature)
Tokenizer creates 77-token prompt chunk embedding from any kind of text (“the prompt”)
CLIP processes a 77-token prompt chunk embedding into 1x768 text encoding
Image (any kind) becomes a 1x768 image encoding (this requires GPU resources).
Image encoding A and Text encoding B “match” are calculated using cosine similarity via the formula below
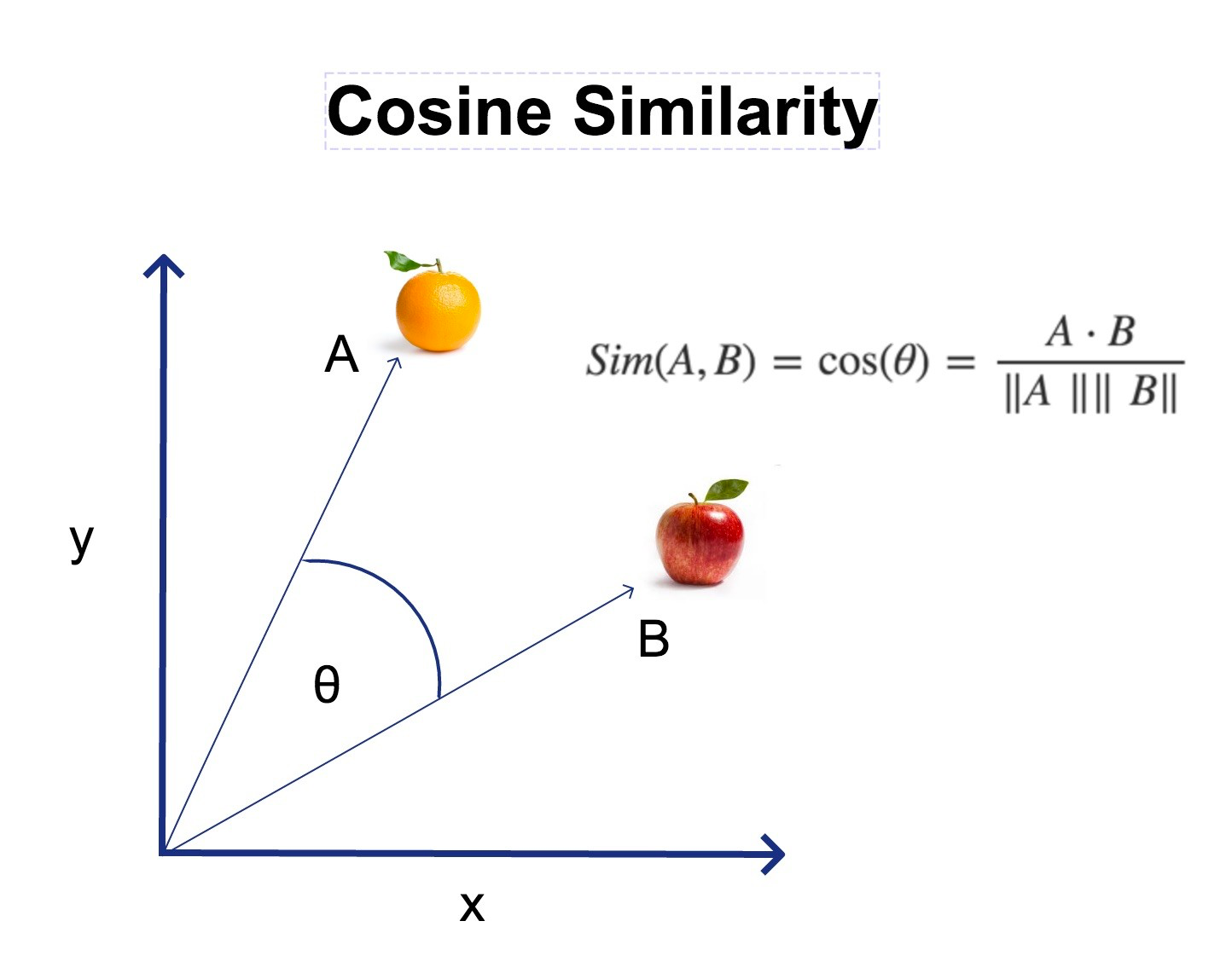
Where the final range from 1 to 0.
1 = 100% match between image A and text B encodings , and 0 = no match at all.
Do this for 1000 text encodings and pick the “text” that gives the highest cosine similarity.
That’s it. Now you have a “prompt” from an image.
//—//