
Heyho,
as a PostgreSQL guy, i’m currently working an tooling environment to simulate load on a lemmy instance and measure the database usage.
The tooling is written in Go (just because it is easy to write parallel load generators with it) and i’m using tools like PoWA to have a deep look at what happens on the database.
Currently, i have some troubles with lemmy itself, that make it hard to realy stress the database. For example the worker pool is far to small to bring the database near any real performance bootlenecks. Also, Ratelimiting per IP is an issue.
I though about ignoring the reverse proxy in front of the lemmy API and just spoof Forwarded-For headers to work around it.
Any ideas are welcome. Anyone willing to help is welcome.
Goals if this should be:
- Get a good feeling for the current database usage of lemmy
- Optimize Statements and DB Layout
- Find possible improvements by caching
As your loved core devs for lemmy have large Issue Tracker backlog, some folks that talk rust fluently would be great, so we can work on this dedicated topic and provide finished PR’s
Greatings, Loki (@tbe on github)
You must log in or register to comment.
Hey! I’m working on a rust tool right now to import a month of reddit dump into a lemmy instance using the federation api (for benchmarking / load testing as well).
Nice! This would greatly help to populate the database and get much better results!
my reddit import code is here for the time being: https://github.com/phiresky/lemmy/tree/reddit-importer
it works but is undocumented
One of the big concerns I have is that there seems to be no sense of the problems being faced. The project was built around very little data for years, and growing pains abound.
As of today, lemmy.ml says this is the posting with the most comments (local), 852: https://lemmy.ml/post/1186515 This federated posting from Beehaw has over 1000: https://lemmy.ml/post/1265302
On Reddit, a moderate news event, such as the discovery of the Titanic submarine this week, can have 10,000 comments - https://old.reddit.com/r/news/comments/14g7ipn/debris_field_discovered_within_search_area_near/
And that isn’t even a major news breaking event on the order of a terrorist attack, Japan earthquake/nuclear incident, famous person being shot, etc.
Yes, i see this issue also. I would assume that the statements used here, tend to get very bad plans, due to overhang (specific id’s will have far more entries then others).
This is one of the reasons for my current setup.
But when it comes to optimizing databases, i think i’m pretty skilled in it, and i have seen much worse scenarios (billing systems, processing > 100.000.000 entries per billing run, with tough time constraints).
Just now they found out that Lemmy is falling over with 300 comment threads.
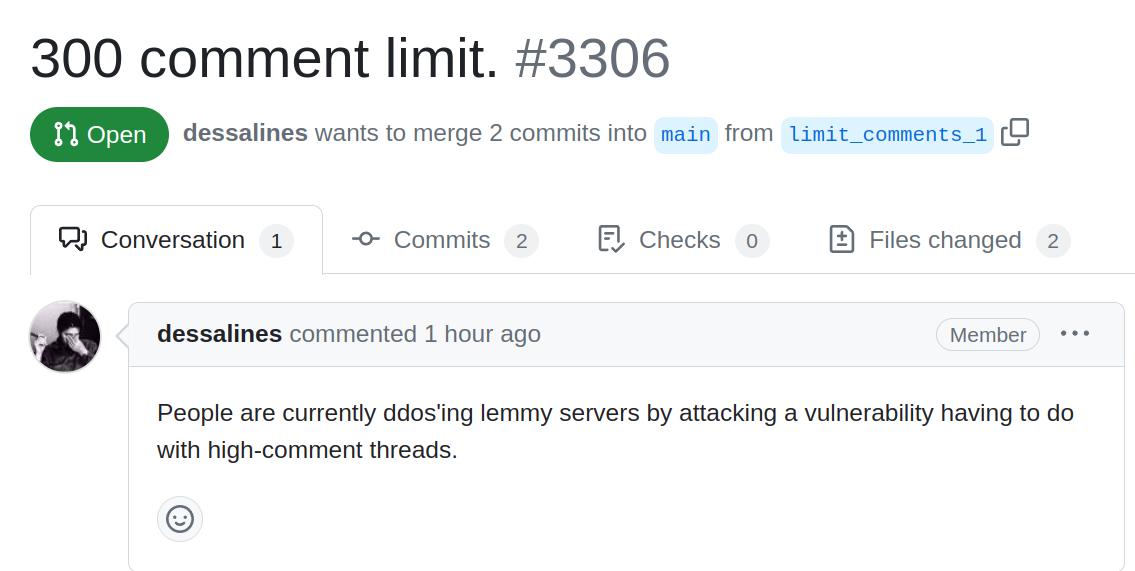
Thx for the heads up. Now, we are talking database ;)
I’ll be upgrading my server to 0.18, I’m mostly using it for testing and code learning.
At this point I don’t have reason to hide the data, here is my two significant server stats:
https://lemmyadmin.bulletintree.com/query/pgcounts?output=table Record counts in tables https://lemmyadmin.bulletintree.com/query/pgstatements?output=table pg_stat_statement extension output, curated columns. Full columns is available if you need it: https://lemmyadmin.bulletintree.com/query/pgstatements1?output=tableFeel free to refresh these pages as much as you like. The pg_stat_statement can be reset, I think I reset them 24 hours ago.
Server is 4 ARM cores, 24 GB of RAM, 200GB IDE level storage performance (Oracle Cloud). There are no interactive users other than myself and perhaps some Google traffic. Federation is the main activity, and I’ve been subscribing to as many big communities as I can for weeks.
Also, Ratelimiting per IP is an issue.
I have concerns about Lemmy having a pattern of hiding these behaviors under the cover. In other words, people running servers having no kind of operator console to know that it is happening. Ideally to me, it would be a setting to adjust in a screen to set for an instance to disable/set threshold. If one doesn’t exist, maybe we can identify where in the code the limit is enforced and hand-edit the code.
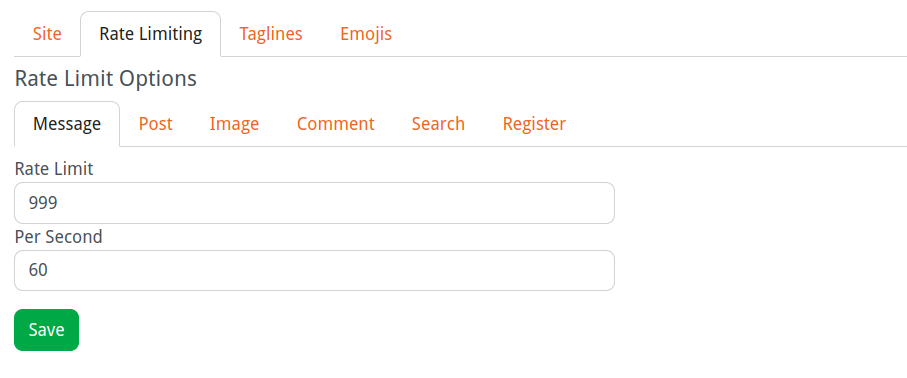
In the site settings, rate limiting can be configured.
But, yes there should be some way to see if limits where hit or not. Maybe this could be done via prometheus and just provide the option to gather this data outside of lemmy itself.
I’m assuming Federation backdoor, API for incoming server to server transactions, doesn’t have a rate limit? But I haven’t validated that assumption.
Maybe this could be done via prometheus and just provide the option to gather this data outside of lemmy itself.
Something, from what I’ve seen so far, Lemmy has no application specific logging and just dumps everything into the system log. I really think operators need some concept of how many signups, logins, post, comments, communities they are getting per hour/day/week - which external websites are out there publishing number of communities and users.
The docker-compose.yml file in the
dockerfolder has a config for postgres logging. We use it to diagnose performance issues in prod. There’s a DB tag on the lemmy issue tracker, I suggest using that to track performance issues.The problem is we need to get some data out of the big sites, Beehaw, Lemmy.ml, Lemmy.world - so that we can see what it is like having far more comments, likes, federation activity, and interactive user loads.
Is someone with a big instance willing to publish their logs?
These log settings are not very good for production. The DB would spend more time logging, then working.
But: We can simulate this kinds of load with local toolings. My first tests look quiet promising, if i would only find the bug in my old pg-exporter i wrote for mal last employer ;) (yes, it is open source).
Maybe @[email protected] can shed some light on this. Not sure if the find time, but it would be great to get some more input.
Current workaround for the Rate limit issue: https://gitea.loki.codes/lemmy-performance/load-test/src/branch/main/pkg/instance/prepare.go#L19
PoWA (PostgreSQL Workload Analyzer)… how much overhead do you think this adds to a server? run in production?
