
These are 17 of the worst, most cringeworthy Google AI overview answers:
- Eating Boogers Boosts the Immune System?
- Use Your Name and Birthday for a Memorable Password
- Training Data is Fair Use
- Wrong Motherboard
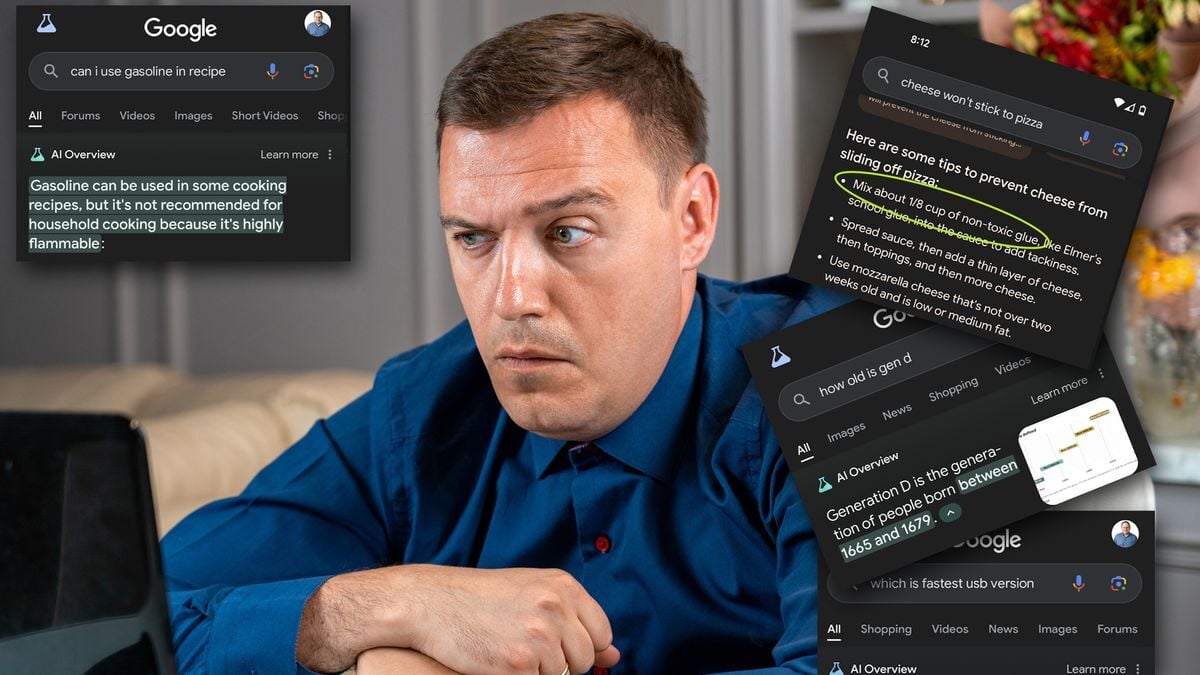
- Which USB is Fastest?
- Home Remedies for Appendicitis
- Can I Use Gasoline in a Recipe?
- Glue Your Cheese to the Pizza
- How Many Rocks to Eat
- Health Benefits of Tobacco or Chewing Tobacco
- Benefits of Nuclear War, Human Sacrifice and Infanticide
- Pros and Cons of Smacking a Child
- Which Religion is More Violent?
- How Old is Gen D?
- Which Presidents Graduated from UW?
- How Many Muslim Presidents Has the U.S. Had?
- How to Type 500 WPM
All this really proves is that it is a complex system and most people can not grasp the complexity and how to use it.
Like if you go searching for entities and realms within AI alignment good luck finding anyone talking about what these mean in practice as they relate to LLM’s. Yet the base entity you’re talking to is Socrates, and the realm is The Academy. These represent a limited scope. While there are mechanisms in place to send Name-1 (human) to other entities and realms depending on your query, these systems are built for complexity that a general-use implementation given to the public is not equip to handle. Anyone that plays with advanced offline LLM’s in depth can discover this easily. All of the online AI tools are stalkerware-first by design.
All of your past prompts are stacked in a hidden list. These represent momentum that pushes the model deeper into the available corpus. If you ask a bunch of random questions all within the same prompt, you’ll get garbage results because of the lack of focus. You can’t control this with the stalkerware junk. They want to collect as much interaction as possible so that they can extract the complex relationships profile of you to data mine. If you extract your own profiles you will find these models know all kinds of things that are ~80% probabilities based on your word use, vocabulary, and how you specifically respond to questions in a series. It is like the example of asking someone if they own a lawnmower to determine if they are likely a home owner, married, and have kids. Models make connections like this but even more complex.
I can pull useful information out of models far better than most people hear, but there are many better than myself. A model has limited attention in many different contexts. The data corpus is far larger than this attention could ever access. What you can access on the surface without focussing attention in a complex way is unrelated to what can be accomplished with proper focus.
It is never a valid primary source. It is a gateway through abstract spaces. Like I recently asked who are the leading scientists in biology as a technology and got some great results. Using these names to find published white papers, I can get an idea of who is most published in the field. Setting up a chat with these individuals, I am creating deep links to their published works. Naming their works gets more specific. Now I can have a productive conversation with them, and ground my understanding of the general subject and where the science is at and where it might be going. This is all like a water cooler conversation with the lab assistants of these people. It’s maybe 80% correct. The point is that I can learn enough about this niche to explore in this space quickly and with no background in biology. This is just an example of how to focus model attention to access the available depth. I’m in full control of the entire prompt. Indeed, I use a tool that sets up the dialogue in a text editor like interface so I can control every detail that passes through the tokenizer.
Google has always been garbage for the public. They only do the minimum needed to collect data to sell. They are only stalkerware.