Somewhat confusing how they present it. As I understand it:
They trained an agent program to play Doom (surely demos or existing bots could do ok at this?)
They use video of the bot playing, along with a list of actions performed, to train an LLM
They use the LLM to generate video of Doom gameplay.
So basically they’re just doing AI video generation, but specialized to only make videos of Doom? I have mixed feelings. This doesn’t seem terribly novel over using any other game or activity to train a specialist video maker. Given the unique properties of Doom, I don’t understand why they didn’t use demos more. Demos (a list of player inputs basically) would seem to be easier to parse with an LLM and easier to generate. Then you can run the demo on an actual copy of Doom and not have these weird visual artifacts.
I suppose the implication is that the LLM has somehow learned the internal rules of Doom and is able to simulate them in the course of generating video. But I don’t buy it. Watch the UI. Sometimes pickups register, sometimes they don’t. Picking up items often results in random amounts of ammo, sometimes of multiple types. Its like how text generators can easily fool people into seeing intelligence by using, essentially, cold reading techniques on them. To a first approximation, it seems like the model “understands” Doom. But it could just as easily be other rules or inferences being made. Maybe when the screen flashes red, it knows health is supposed to decrease by some amount? Maybe it’s good at picking up regular temporal events, so it can replicate the DoT from standing in nukage, but doesn’t truly understand why that’s happening so sometimes health just randomly tics down by a point or two for no reason?
Mostly, I just see an attempt to normalize the idea that “Generative AI belongs in (and can replace, lol) actual game engines”. Please hire us and pay us exorbitant amounts of money to ruin your game engines.
They trained an agent program to play Doom (surely demos or existing bots could do ok at this?)
They probably had that lying around anyway. Traditional bots follow pre-programmed paths, a navmesh. I don’t think you’d get the more organic, exploring gameplay out of those that’s necessary here. They say there’s not enough recorded gameplay from humans.
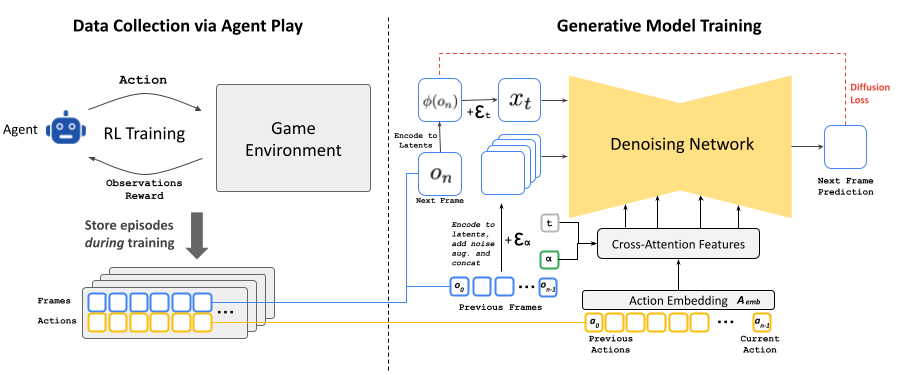
They use video of the bot playing, along with a list of actions performed, to train an LLM
No, they trained Stable Diffusion 1.4; a so-called latent diffusion model. It does text-to-image. You’re probably aware of such image generators.
They trained it further for their task; to take frames and player input as a prompt instead of text. On google hardware, they get 20 fps out of the AI, which is just enough for humans to play the game, in a sense.

Somewhat confusing how they present it. As I understand it:
So basically they’re just doing AI video generation, but specialized to only make videos of Doom? I have mixed feelings. This doesn’t seem terribly novel over using any other game or activity to train a specialist video maker. Given the unique properties of Doom, I don’t understand why they didn’t use demos more. Demos (a list of player inputs basically) would seem to be easier to parse with an LLM and easier to generate. Then you can run the demo on an actual copy of Doom and not have these weird visual artifacts.
I suppose the implication is that the LLM has somehow learned the internal rules of Doom and is able to simulate them in the course of generating video. But I don’t buy it. Watch the UI. Sometimes pickups register, sometimes they don’t. Picking up items often results in random amounts of ammo, sometimes of multiple types. Its like how text generators can easily fool people into seeing intelligence by using, essentially, cold reading techniques on them. To a first approximation, it seems like the model “understands” Doom. But it could just as easily be other rules or inferences being made. Maybe when the screen flashes red, it knows health is supposed to decrease by some amount? Maybe it’s good at picking up regular temporal events, so it can replicate the DoT from standing in nukage, but doesn’t truly understand why that’s happening so sometimes health just randomly tics down by a point or two for no reason?
Mostly, I just see an attempt to normalize the idea that “Generative AI belongs in (and can replace, lol) actual game engines”. Please hire us and pay us exorbitant amounts of money to ruin your game engines.
Not quite.
They probably had that lying around anyway. Traditional bots follow pre-programmed paths, a navmesh. I don’t think you’d get the more organic, exploring gameplay out of those that’s necessary here. They say there’s not enough recorded gameplay from humans.
No, they trained Stable Diffusion 1.4; a so-called latent diffusion model. It does text-to-image. You’re probably aware of such image generators.
They trained it further for their task; to take frames and player input as a prompt instead of text. On google hardware, they get 20 fps out of the AI, which is just enough for humans to play the game, in a sense.