From my extremely limited understanding, it’s because of the sheer scale of the data that’s been fed into LLMs, and because of the (admittedly small) possibility that the people working on LLMs never really took the time to understand what sort of connections the LLM was making between all the datapoints it was interacting with and drawing connections between, or at least a deeper understanding of how the math worked; just that it did.
As the scale of the project kept growing and LLM companies just kept throwing ‘more data, more neural networks, more hardware!’ into the mix, the black box became…well, blacker and it kept getting harder to figure out the internal ‘logic’ used by the LLM to predict the next word. Now, the people who’re trying to figure it all out are working with extremely large amounts of data with nothing to go off of.
In short, the people making GPT were somehow smart enough to make it, but not smart enough to understand what they were making.
It’s not that nobody took the time to understand. Researchers have been trying to “un-blackbox” neural networks pretty much since those have been around. It’s just an extremely complex problem.
Logistic regression (which is like a neural network but with just one node) is pretty well understood - but even then sometimes it can learn some pretty unintuitive coefficients and it can be tricky to understand why.
With LLMs - which are enormous by comparison - it’s simply not a tractable problem to understand how it works in detail.

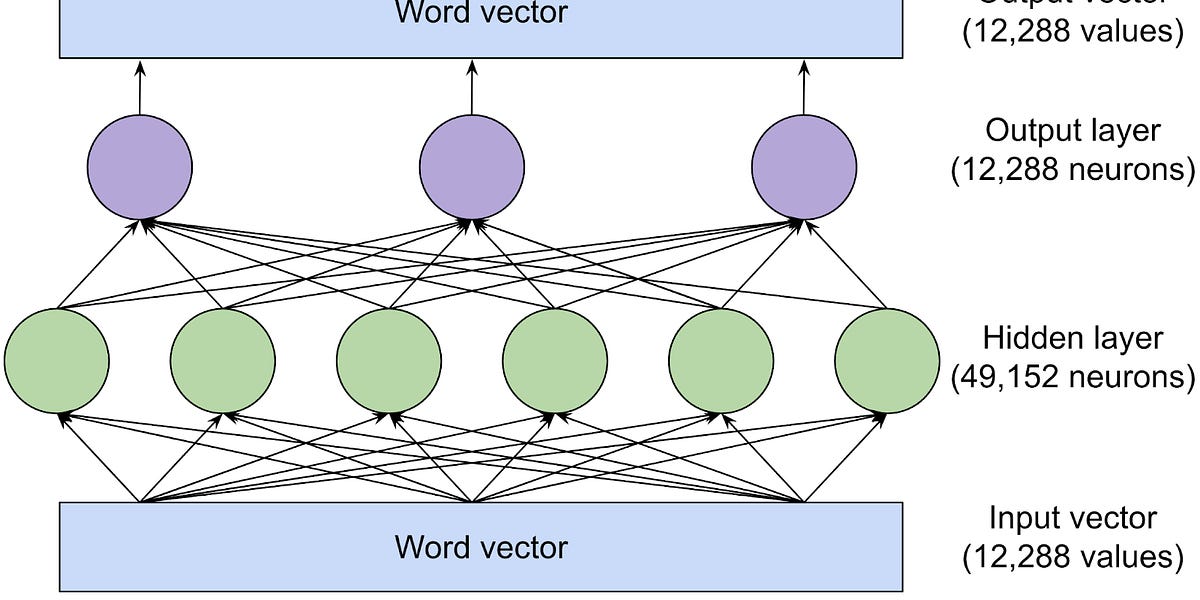
From my extremely limited understanding, it’s because of the sheer scale of the data that’s been fed into LLMs, and because of the (admittedly small) possibility that the people working on LLMs never really took the time to understand what sort of connections the LLM was making between all the datapoints it was interacting with and drawing connections between, or at least a deeper understanding of how the math worked; just that it did.
As the scale of the project kept growing and LLM companies just kept throwing ‘more data, more neural networks, more hardware!’ into the mix, the black box became…well, blacker and it kept getting harder to figure out the internal ‘logic’ used by the LLM to predict the next word. Now, the people who’re trying to figure it all out are working with extremely large amounts of data with nothing to go off of.
In short, the people making GPT were somehow smart enough to make it, but not smart enough to understand what they were making.
It’s not that nobody took the time to understand. Researchers have been trying to “un-blackbox” neural networks pretty much since those have been around. It’s just an extremely complex problem.
Logistic regression (which is like a neural network but with just one node) is pretty well understood - but even then sometimes it can learn some pretty unintuitive coefficients and it can be tricky to understand why.
With LLMs - which are enormous by comparison - it’s simply not a tractable problem to understand how it works in detail.