
{kind=link}
- cross-posted to:
- [email protected]
- cross-posted to:
- [email protected]
Previous posts: https://programming.dev/post/3974121 and https://programming.dev/post/3974080
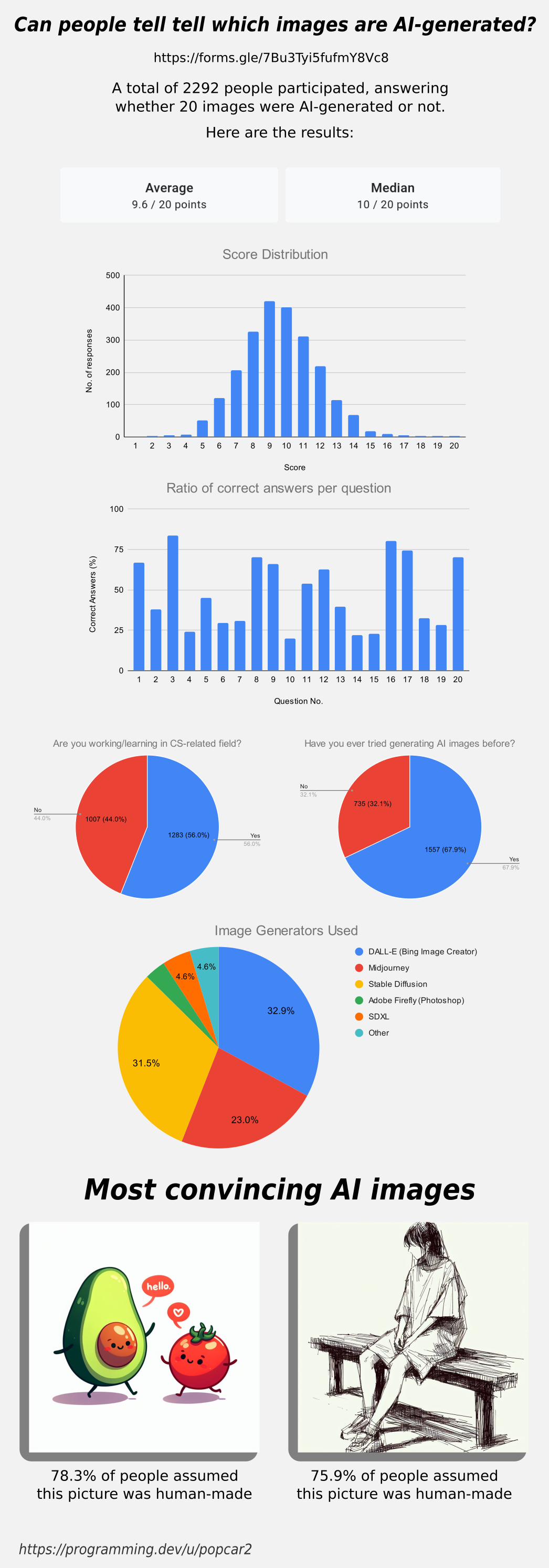
Original survey link: https://forms.gle/7Bu3Tyi5fufmY8Vc8
Thanks for all the answers, here are the results for the survey in case you were wondering how you did!
Edit: People working in CS or a related field have a 9.59 avg score while the people that aren’t have a 9.61 avg.
People that have used AI image generators before got a 9.70 avg, while people that haven’t have a 9.39 avg score.
Edit 2: The data has slightly changed! Over 1,000 people have submitted results since posting this image, check the dataset to see live results. Be aware that many people saw the image and comments before submitting, so they’ve gotten spoiled on some results, which may be leading to a higher average recently: https://docs.google.com/spreadsheets/d/1MkuZG2MiGj-77PGkuCAM3Btb1_Lb4TFEx8tTZKiOoYI
This isn’t possible as of now, at least not reliably. Yes, you can tailor a model to one specific generative model, but because we have no reliable outlier detection (to train the “AI made detector”), a generative model can always be trained with the detector model incorporated in the training process. The generative model (or a new model only designed to perturb output of the “original” generative model) would then learn to create outliers to the outlier detector, effectively fooling the detector. An outlier is everything that pretends to be “normal” but isn’t.
In short: as of now we have no way to effectively and reliably defend against adversarial examples. This implies, that we have no way to effectively and reliably detect AI generated content.
Please correct me if I’m wrong, I might be mixing up some things.
deleted by creator
I said “reliably”, should have said “…and generally”. You can, as I said, always tailor a detector model to a certain target model (generator). But the reliability of this defense builds upon the assumption, that the target model is static and doesn’t change. This is has been a common error/mistake in AI research regarding defensive techniques against adversarial examples. And if you think about it, it’s a very strong assumption, that doesn’t make a lot of sense.
Again, learning the characteristics of one or several fixed models is trivial and gets us nowhere, because evasive techniques (e.g. finding ‘adverserial examples against the detector’ so to speak) can’t be prevented as of know, to the best of my knowledge.
Edit: link to paper discussing problems of common defenses/attack scenario modelling https://proceedings.neurips.cc/paper/2020/hash/11f38f8ecd71867b42433548d1078e38-Abstract.html
deleted by creator