
Hey all, new to this and pretty amazed at the quaity of the text to photos I’m getting. Working to create players on a baseball team. What is way to add grass stains or dirt from sliding to a uniform?Only a little dust shows up no matter what I prompt, and usually there’s nothing. Doesn’t seem to want to put a stain on white pants, lol. Any ideas? thx
Didn’t know about the prompt getting read from left to right, that helps to prioritize. Once I get a good image, how to use the seed? When I copy the seed into the prompt, I get 12 identical images., not identical to the seed. Can I build off the preferred image. Does the seed need to presented in parentheses? thx
Stable Diffusion works by converting purely random noise to an image that matches the prompt.
The reason for this is because Stable Diffusion was trained with billions of existing image + description pairs.
A little bit of “noise” was added to each image and Stable Diffusion was tasked to modify itself so it could “fill in the gaps” , until it reached a point where it could convert pure noise to an image using a prompt.
The random noise is generated from the seed.
The image generation process is deterministic , so same seed for a given prompt => same image.
Best not bother with the seeds IMO.
Seeds are only ever useful when you want to demonstrate/compare stuff.
If you get a good image , it’s better to copy paste the start of the prompt and shift around the stuff at the end.
Given the “left-to-right” rule , the first two tokens are the most important thing in your prompt.
Ideally , you want to keep those two tokens as vague as possible , e.g instead of “dog with red ball” you write “look at this dog with a red ball here” , or something.
Note that I added the token “here” at the end as well , so we get the association “ball->here” in addition to the “red->ball” .
TLDR : "vague stuff A " “the prompt” “vague stuff B” ,
is sort of how you want to style the prompt.
If image is good , keep “vague stuff A” and shift “vague stuff B” around .
// — //
Also note that I’m writing this just to show how it works. There is no “correct” way to prompt.
There is more stuff related to tokens and cross-attention but I’m skipping it because I don’t want to write more.
But you can see it’s kind of a large subject :)
and i have no idea about tokens nor seeds lol! you clearly are the tokenmaster tho
about to delve in to seeds right now tho and post back what i learn
i’ve learned b4 that generating an image with the same seed comes out more ‘not identical’ the more tokens are used even tho it is said they are identical.
just now i made image 1 seed 1, image 2 seed 2, etc up to seed 6.
first prompt was ‘cute kitty’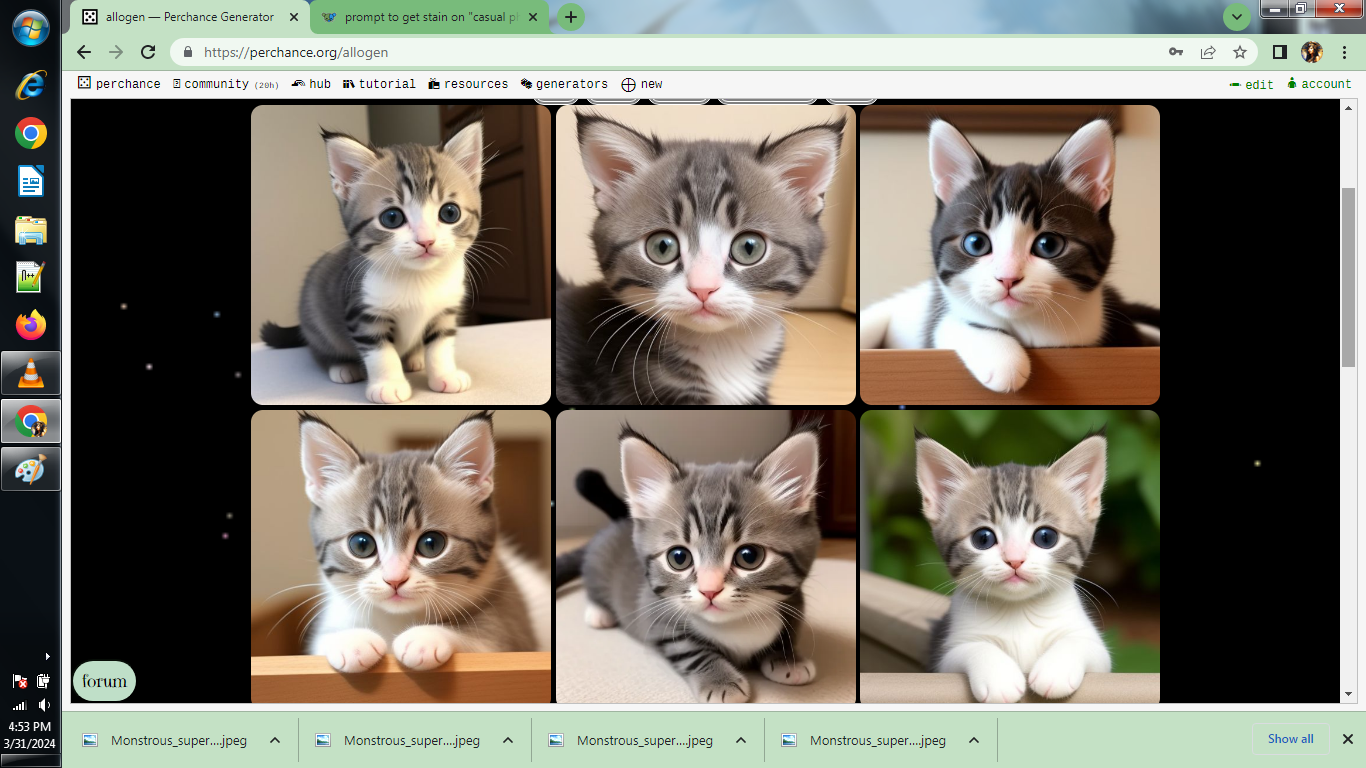 notice the extradark kitty in top right
notice the extradark kitty in top right
i did this once on one of Vione’s generators and got the EXACT same person wearing a different outfit.
my guess is the top right seed has a little bit more dark pixels in a certain region than the other pictures. I have tended to agree with adComfortable and not even included seed options in my generators, and it seems very easy to entirely change the entire picture with a single change or addition of a word, tho nice topic and i will probably get back to you in a week after having added the ability to save seeds of good images and then mess with them and see just how buildable or not buildable they are while keeping the soul coherent.
cute kitty top right also prefers right paw forward
Cool!
One minor thing I forgot to say ; the “noise” isn’t pixels in an image.
The “noise” is a purely mathematical abstract concept here , commonly referred as latent noise .
I have no idea if saving the seed for a “good image” will yield the similiar “good results” with a different prompt.
I’d be happy to hear if you discover something :)!
In my generator I use a different approach by pre-rendering the image with the “Base”-prompt , switching over to the “Main” prompt after 10% of the generation steps (be default).
Unlike seeds , that is actually a partially rendered image which is filled in. So this is another option to use.
wow! sounds like an entire artform you are tapped in to
Definitely something to using the same seed to retain the same character.
even switching some words toward the front around (adding ‘oceanic’ as the second word to see if i could turn the blue to water) kept large amounts of the image, including the character, mostly the same.
it is surprisingly easy to keep large chunks the same. definite more to explore
that is ‘master planner girl’. didn’t say anything about her hair color nor style, yet something is holding it the same on the same seed. tho also even with identical seed and prompt it seems generating 6 pics results in 4 or 5 slightly different ones with, for master planner girl, the one where she is looking forward and slightly to the side being her two main image types
Thanks :)! I hardly use seeds at all so I’d be happy to hear if you discover a cool usage for them
Also; I have token-word generators , if you wish to use them for your image generator.
Here is the common-token generator : https://perchance.org/fusion-sd15-clip-tokens-common
There are 5 sets based on their ID number ( their prevalence in the training data) ; common , average , rare , weird , exotic .
I use them in my generator but here is a version made by Vionet20 which I think is much better for demonstration purposes : https://perchance.org/prompts-from-tokens
yes it does in that exact format unless you make a generator in which the image plugin takes an object with variables as it’s source, in which case you can have a variable be ‘seed’ and specify it’s number