
https://chrome.google.com/webstore/detail/wayback-machine/fpnmgdkabkmnadcjpehmlllkndpkmiak
https://addons.mozilla.org/en-CA/firefox/addon/wayback-machine_new/
It will also detect when a webpage you are trying to visit is dead and will offer to replay an archived version
You must log in or register to comment.
My desire to help archive.org preserve the Internet is conflicting with my desire not to have anybody tracking my browsing habits.
I get you, the internet archive is a good cause however
I’m also conflicted, I’ve saved this post for now, maybe I decide to use the extension at some point.
Does it really need to back up THAT much porn?
Listen, you can just tell people you’re doing your part in preserving history
https://en.wikipedia.org/wiki/Erotic_art_in_Pompeii_and_Herculaneum#/media/File:Fresco_en_el_lupanar,_Pompeya._05.JPG yep, wish there were more of these
Digital is only permanent if we duplicate everything y’all
Awesome, will start using this.
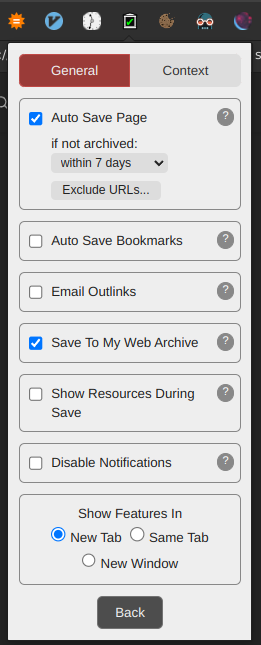
I believe the automatic archiving has to be manually enabled by going to the settings, selecting the general tab and enabling “Auto save page”.
Thanks, I just looked at my settings and realized that I hadn’t checked that box.
Tbh, most websites I visit probably aren’t that important that they need to be archived. I would assume installing this extension would just contribute to a bloated archive with little additional value.
From my understanding, the Internet Archive’s goal (granted that they manage to get through their current dilemma) is to archive the whole Internet, I wouldn’t consider it to be bloat.
Is this just for personal purposes or would I be contributing to the internet archive?
Purely to contribute to the internet archive. There’s the “save page now” button that’ll save the webpage to your account, but the automatic downloader that I refer to in the post doesn’t do that and is purely for the sake of expanding the archive.
How safe is it to have automatic page saving enabled when using websites that require an account? Can it potentially dox oneself?
it doesn’t literally scrape the web page off your browser, it just sends a download request to the internet archive to download the webpage associated with the URL that you’re visiting
-replying from kbin because lemmy just wouldn’t let me reply… I’d been trying for over 20 minutes.
I wasn’t sure if it was using the client to capture the snapshot or not, better safe than sorry! Thanks for explaining.
The I’ll definitely be doing this. Happy to contribute to the archive, especially because it came in clutch during the other site’s blackout. Digital preservation is not supported enough
…now where is my external hd.




{kind=link}