
Prompts are in the fusion generator. Would be fun to see people post their own creations on this lemmy-community so I’d figure I take the initiative :)
Click to show gallery
A1-A2


B1-B2


C1-C2


D1-D2


E1-E2


F1-F2


G1-G2


E1-E2


🔸✨📝🔰🔹 Continued.
Click to show gallery (part 2)
F1-F2


G1-G2


H1-H2


I1-I2


J1-J2


K1-K2


<3 h1 fluttershy
you have such diversity
🔞 NSFW content below 🔞
I have a fun idea. Let’s use this opportunity to showcase how from-to-steps works.
It’s easier to demonstrate this feature for NSFW content.
Disclaimer : Note that there is no correct way to prompt stuff. Any method is valid. This tutorial is intended to show the features of the fusion generator.
Step 1 :
Let’s start with showing a custom ✨ Base prompt
✨ PROMPT : " grainy recording from beneath waist closeup she #name# and #name2# wearing white leotards on orange ambient on orange ambient teal bathroom "
🚫 NEG : “”

We utilize this kind of boring prompt to generate unique skin-tones and/or perspectives.
Step 2 (🔞 nsfw) :
Now we switch from the ✨ Base -> to the 📝 Main prompt after 10% of the generation steps
✨-> 📝 PROMPT : "[ grainy recording from beneath waist closeup #name# and #name2# wearing white leotards on orange ambient on orange ambient teal bathroom : exposed wet nudephotography sweaty red tanned she Emily and her younger sister candid view stockphoto :0.1] "
🚫 NEG: (empty)

Note the “bad ai art features” here: Symmetric bodies ,faces etc.
Fixing these issues is the main purpose of the 🔸✨📝🔰🔹 Fusion AI Image generator.
Let’s start by adding a seemingly paradoxical choice of words in the “🚫 Delayed Negative Prompt” in the next step.
Step 3 (🔞 nsfw) :
Right now , the prompt is :
✨-> 📝 PROMPT : "[ … : exposed wet nudephotography sweaty red tanned she Emily and her younger sister candid view stockphoto:0.1] "
🚫 NEG : “[:girls african white women bath female:0.7]”



As you can see the delayed negatives yield more unique body poses and shapes. A short explanation why this paradoxical approach works this way is because SD is an optimization problem and the negatives are delayed in this generator. There is more info in the tutorial section for the generator.
Step 4 ( 🔞 nsfw) :
We now add an obscure #suffix# token in the beginning.
By obscure , we mean placing a token with a high ID number into the prompt. You can find the ID number in the vocab.json file for SD 1.5
Next , we replace the name “Emily” with the #name# dataset.
Finally, we randomly add 3 #rareSuffix# tokens to the 🚫 Delayed Negative Prompt.
✨-> 📝 PROMPT : “[ … : #suffix# exposed wet nudephotography sweaty red tanned #name# and #name2# candid view stockphoto : 0.1]”
🚫 NEG : [ : girls african white women bath female #rareSuffix1# #rareSuffix2# #rareSuffix3# : 0.72]








Here we see the key difference between obscure and common tokens. SD knows what to do when a common tokens is placed , but is more “unsure” how to interpret an obscure token.
Hence , by placing an obscure token in the beginning we can drastically improve the range of “freedom”. As you can see, adding just a single obscure token in the beginning allows us to to twist the body shapes in all sorts of configurations!
We can also see the downside with obscure tokens , in that the obscure token(s) sometimes create tiny “weird pieces of stuff” in the image.
Step 5 ( 🔞 nsfw) :
To fix this issue we need to add more common tokens to the prompt. The #lyrics# dataset is created for this purpose.
Unlike #suffix#, which generates a single random suffix-token from the SD 1.5 CLIP tokens , the #lyrics# tokens is verse from a song.
✨-> 📝 FINAL PROMPT : "[ … : #suffix# #lyrics# exposed wet nudephotography sweaty red tanned #name# and #name2# candid view #lyrics2# stockphoto : 0.1] "
🚫 FINAL NEG : [ : girls african white women bath female #rareSuffix1# #rareSuffix2# #rareSuffix3# :0.72]
This is a useful dataset as a) #lyrics# will generate a series of very common words (read: tokens) that are “strong” at hence generate a lot of consistency and variety. This will (usually) eliminate a lot of the tiny “junk” we get in the image from using obscure tokens.
The specific reason why I choose verses from songs is because these are sentences are very vague in what they mean , I can thus be inserted into any prompt without interfering with the “main stuff” so-to-speak. The prompt is essentially a lottery at this point , but we still keep the overall concept:




Feel free to experiment yourself past this point. All prompts from above images are found in the fusion generator for reference.
great tutorial! Seems for me like the next big powerful thing I’ve never explored. and interesting the thing about how ai is bad at varying multiple faces. i’ve seen people put ‘clone’ and maybe ‘cloned face’ in their antiprompt. maybe some exploration in to that would yield results?
Thanks. Sure , go wild :) !
If we look at the vocab.json we see that “clone</w>” has the ID 22854 , so kind-of in the middle of the full 47K set of tokens.
“Clone” might be a term used more in biomedicine training data than in scifi training data , e.g. “cloned cells” and so on.
I’d assume the “strength” of a single token (e.g how familliar SD is with using that token together with other token) , is NOT linearly proportional to the ID:s , but exponential like (or possibly exactly like) in a Gauss Bell curve.
It’s hard to describe with words so I here is stuff I have written on a bell curve to show my perspective on the IDs in relation to their “linguistic commonality”.
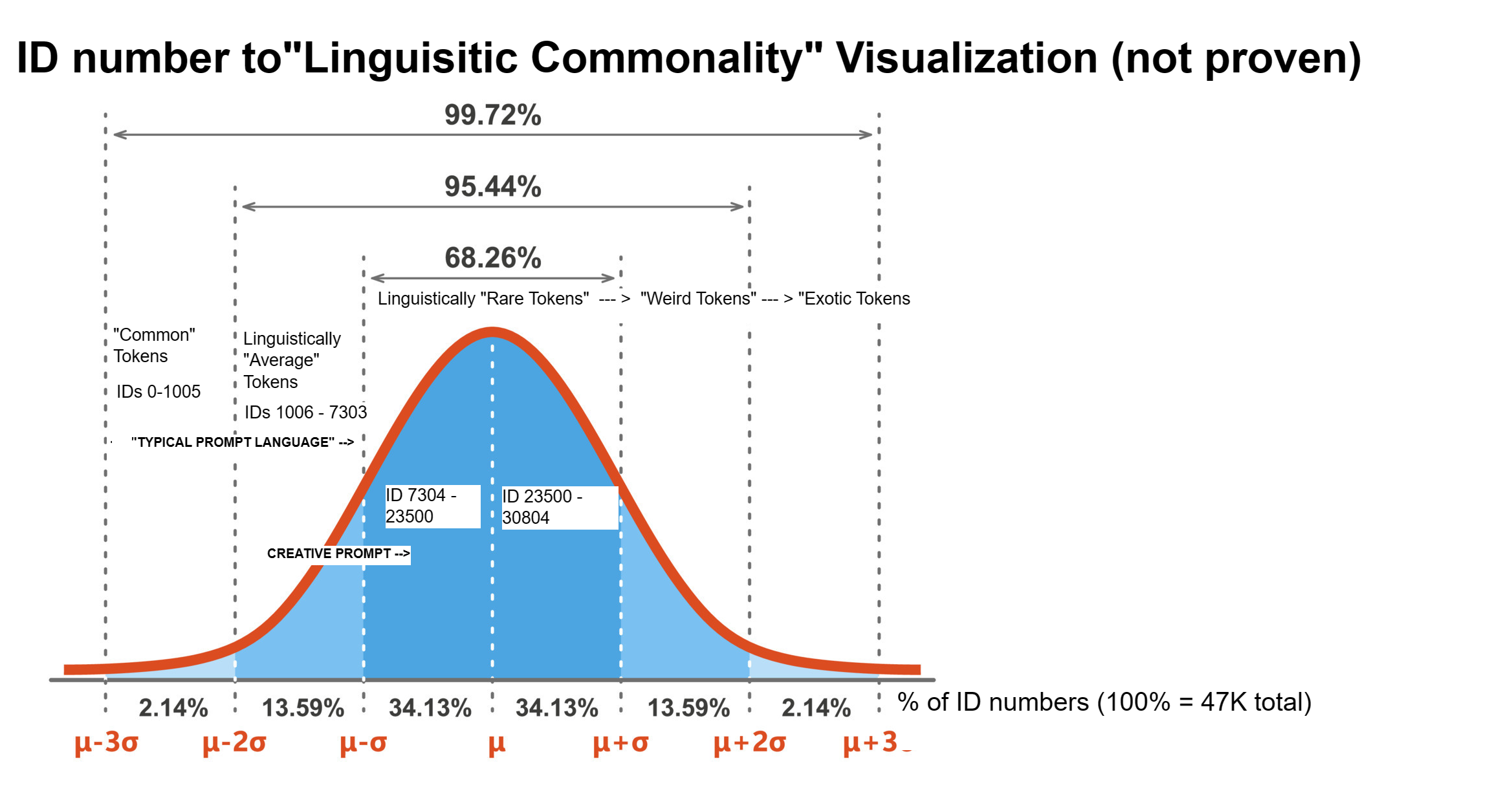
Full disclosure : I haven’t balanced the Common/Average/Rare/Weird/Exotic categories yet.
I think the ID distribution is an arbitrary sort-of even split of the ID numbers , currently.
I welcome suggestions/ideas on how to distribute these tokens to their given category.
Since we sample “rareSuffix” 3 times it might be better to write stuff in the common category , e.g. “twins</w>” for ID 8040 or “same</w>” for ID 2208.
But it’s not that simple either. Because you can have a token that is very obscure that under the right conditions will form very strong association with other tokens or with the rendered image itself thus far . The latter part important to consider when using delayed prompts.
So it’s all a lottery really. Do you want to prompt “safe” in the negatives by placing common tokens with a high % likelyhood of strong association between adjecent word and rendered image thus far.
Or do you want to “bet big” for the “jackpot” and use very obscure tokens that might not do anything useful , but on a rare % create very strong association to something , and create something really , really unique?
It’s so much thinking that the easiest option , in my option , is to just use whatever words come to mind.
im starting a part of beautiful-people today which links to these educational posts (currently on the ? button of it, but will give it it’s own spot i think. brings to light a nice use of this forum too. may make sense to make a high quality standalone post on every facet of our image generation)
Hmm. Yeah , things are a bit scattered at the moment.
If it’s easier for you , you can copy-paste or rewrite the information I’ve provided on your generator.
Showing NSFW images on the generator page without a filter may impact search engine results , so having it linked here is safer , I think.
Plus it will be free advertisement for this forum :)!
Though in long term , maybe its better to have a dedicated separate forum just for NSFW stuff? I don’t know.
You could also use the spoiler tags in Lemmy for NSFW stuff:
::: spoiler Click Here to Show Content Here is the content inside it :) :::Which results to:
Click Here to Show Content
Here is the content inside it :)
Super useful! Thanks :)!
I could post some but my gallery is only nsfw
Thats fine by me. Upvoted.
Might be prudent to avoid 100% NSFW focused posts for the time being , and instead keep NSFW+SFW stuff “in bulk” together.
I’ll rewrite the post as SFW+NSFW in comments to make things easier for everybody
deleted by creator



![[Gallery] Examples from the 🔸✨📝🔰🔹 fusion T2I generator , feel free to post your own stuff (SFW , but NSFW in comments) EDIT: Tutorial added](https://lemmy.world/pictrs/image/0c8d09fe-feb6-4443-b703-894bb2d42ae1.jpeg){kind=link}