


You must log in or register to comment.
Good, that shitty OpenAI needs to be drained dry and go into nonexistence ASAP.
Who do you think they are draining ?
do you think the answer is “normal people with normal lives”?
it really ain’t.
Whose labour got exploited for micro-shit to have this much capital to blow?
I mean I ain’t gonna cry about them potentially losing it but let’s be real we are still a paying for this.
They get to take risks, if they win, it theirs. If they lose ohh well crack the whips to make up the diffefrence
They are draining their capital investment. Their employees are not paying the 5b.
I don’t think you understand how things really work lol
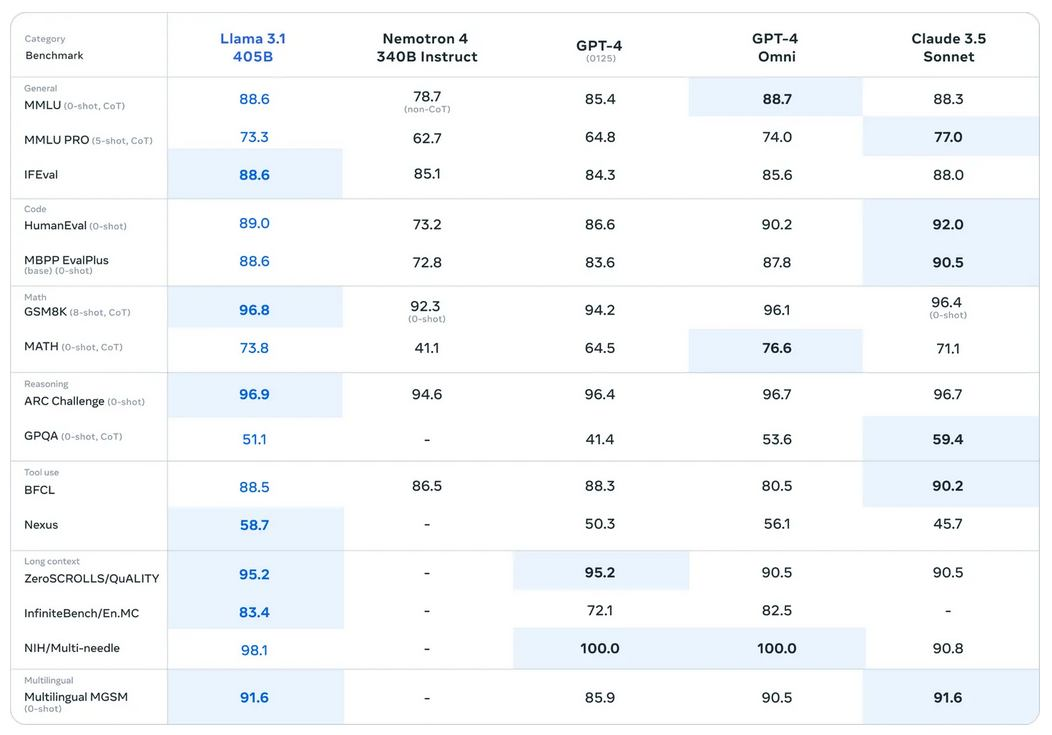
Yann and co. just dropped llama 3.1. Now there’s an open source model on par with OAI and Anthropic, so who the hell is going to pay these nutjobs for access to their apis when people can get roughly the same quality for free without the risk of having to give your data to a 3rd party?
These chuckle fucks are cooked.
For “free” except you need thousands of dollars upfront for hardware and a full hardware/software stack you need to maintain.
This is like saying azure is cooked because you can rack mount your own PC
OpenAI is losing money on every user and has no moat other than subsidies from VCs, but that’s ok because they’ll make it up in volume.
That’s mostly true. But if you have a GPU to play video games on a PC running Linux, you can easily use Ollama and run llama 3 with 7 billion parameters locally without any real overhead.
Just an off-the-cuff prediction: I fully anticipate AI bros are gonna put their full focus on local models post-bubble, for two main reasons:
-
Power efficiency - whilst local models are hardly power-sippers, they don’t require the planet-killing money-burning server farms that the likes of ChatGPT require (and which have helped define AI’s public image, now that I think about it). As such, they won’t need VC billions to keep them going - just some dipshit with cash to spare and a GPU to abuse (and there’s plenty of those out in the wild).
-
Freedom/Control - Compared to ChatGPT, DALL-E, et al, which are pretty locked down in an attempt to keep users from embarrassing their parent corps or inviting public scrutiny, any local model will answer whatever dumbshit question you ask for make whatever godawful slop you want, no questions asked, no prompt injection/jailbreaking needed. For the kind of weird TESCREAL nerd which AI attracts, the benefits are somewhat obvious.
you almost always get better efficiency at scale. If the same work is done by lots of different machines instead of one datacenter, they’d be using more energy overall. You’d be doing the same work, but not on chips specifically designed for the task. If it’s already really inefficient at scale, then you’re just sol.
I guess it depends how you define what an “ai bro” is. I would define them as the front men of startups with VC funding who like to use big buzz words and will try to milk as much money as they can.
These types of people don’t care about power efficiency or freedom at all unless they can profit off of it.
But if you just mean anyone that uses a model at home then yeah you might be right. But I’m not understanding all the harsh wording around someone running a model locally.
deleted by creator
-
The whole point of using these things (besides helping summon the Acausal Robot God) is for non-technical people to get immediate results without doing any of the hard stuff, such as, I don’t know, personally maintaining and optimizing an LLM server on their llinux gaming(!) rig. And that’s before you realize how slow inference gets as the context window fills up or how complicated summarizing stuff gets past a threshold of length, and so on and so forth.
Azure/AWS/other cloud computing services that host these models are absolutely going to continue to make money hand over fist. But if the bottleneck is the infrastructure, then what’s the point of paying an entire team of engineers 650K a year each to recreate a model that’s qualitatively equivalent to an open-source model?
For me, the bottleneck is my data. I want to keep my data. And honestly I don’t know why any entity is OK with sharing their data for some small productivity improvements. But I don’t understand a lot.
The engineers can generally also do other things, the security will likely be better, and its fully possible API costs will exceed that sum if you need that much expertise inhouse to match your API usage.
The engineers can generally also do other things
What’s the job posting for that going to look like, LLM stack maintainer wanted, must also be accomplished front end developer in case things get slow?
That’s completely true but the model that is beating OpenAI and Claude is 405b parameters. Those small models are catching up very fast and it’s impressive what can be run on consumer GPU but you need a monster rig to run the full 405b even at small quants.
Dumbass detected
Correct, they’re 👆 here
Incoming ban from site detected.
What’s your point
That the assman is, indeed, dumb?
a Dumbassman, if you will
Unless they get that infinite money cheat code from Robinhood securities
Dear CHATGPT how do we get our company more money?
“That’s a great question. To get more money simply bring up the console and enter ‘rosebud!;! ;! ;! ;!’”
all of the others next please
Oh no!
Anyway.
Another classic Samai photo
it’s the best samalt photo
These fucking assholes.
Dear Santa, please let OpenAI double its net profits.






