

Joel Bethke @Fenrirthviti · 1 day ago Author
As an update to everyone following, I had a meeting today with the Flatpak SIG and Fedora Project Leader, which was a very good conversation. We discussed the issues, how we got here, and what next steps are. For anyone not interested in the specific details, the OBS Project is no longer requesting a removal of IP or rebrand of the OBS Studio application provided by Fedora Flatpaks.
This issue should be used for tracking of the other specific, technical issues, that the Fedora Flatpak does still have, which I will address below.
From our perspective, there were two key points that we feel are the most important to address:
The issue with the Qt runtime having regression
The issue of not knowing where to report bugs for what is a downstream package
For the first bullet, this should be resolved with the update to the latest runtime, which includes Qt 6.8.2 that has the fixes for those regressions in it.
For the second, this is obviously a much larger issue to tackle, especially for a project as large as Fedora. We had some very good discussion on how this might be accomplished in the medium-long term, but don’t consider it a blocker at this point. We plan to stay engaged and offer our perspective as an upstream project.
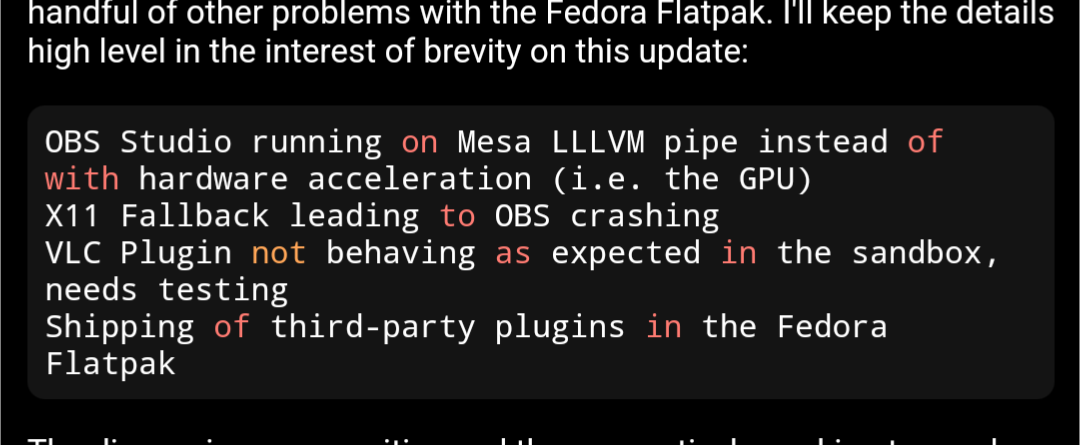
In addition to those two previously blocking issues, we discussed a handful of other problems with the Fedora Flatpak. I’ll keep the details high level in the interest of brevity on this update:
OBS Studio running on Mesa LLLVM pipe instead of with hardware acceleration (i.e. the GPU)
X11 Fallback leading to OBS crashing
VLC Plugin not behaving as expected in the sandbox, needs testing
Shipping of third-party plugins in the Fedora Flatpak
The discussion was positive and they are actively working to resolve those issues as well, which should hopefully only affect a small number of users.
I would like to give a final thank you to Yaakov and the FPL for taking the time to talk to us today.
It’s refreshing to see differences hashed out and solved in a productive manner. Props to both OBS and the Fedora Flatpak team!
Can someone explain the purpose and perceived value of color coding certain words and phrases? I assume this is some new fad along the lines of "As ______, I want to _______ with ________” in writing user stories and requirements.
The OP should have used the Markdown for quote instead of code.
Quote Rendered:
this is a quote
Quote Markdown:
> this is a quote
Multiple Paragraph Quote Rendered:
this is a quote
with multiple paragraphs
Multiple Paragraph Quote Markdown:
>this is a quote > >with multiple paragraphs
Inline Code Rendered:
this is an
inline codeexampleInline Code Markdown:
this is an
`inline code`example
Code Block Rendered:
this is a code blockCode Block Markdown:
``` this is a code block ```
Text-defined Code Block Rendered:
this is a text-defined code blockText-defined Code Block Markdown:
```text this is a text-defined code block ```
TIL you can actually specify the language of a code block. I didn’t know you could do that, and figured the syntax highlighting was therefore useless.
int foo(int bar, char* baz): printf("here's some C code in a 'c' code block\n"); return 0; }def foo(bar, baz): print "here's some Python code in a 'python' code block"I do think it’s stupid to have syntax highlighting by default without a language specified, though – the behavior you label ‘text-defined’ should be the default. What language is the default highlighting even for, anyway?
That’s a very good question. So good, I didn’t feel right just posting:
code
I think this has been put in a code block and this Lemmy thinks it is code hence why it is highlighting specific words to make it easier to read if it was actual code.
What color coding do you mean?
This is what it looks like for me in Voyager:

As several people have already mentioned, it’s because when they posted it, they used a code block instead of a quote block, so the client is rendering it like it was source code.
they used a code block instead of a quote block
I wish Lemmy supported a quote block of some kind. Instead, the only way to quote multiple paragraphs is to place a
at the beginning of every single paragraph, including at every single blank line between paragraphs. When trying to quote an entire news article or something, I usually end up pasting the text into a text editor, doing a find/replace to replace all newlines with a newline and, then copy/paste all that into Lemmy. Some syntax like this would be useful to render a multi line quote block:>>> Paragraph 1 Paragraph 2 Paragraph 3 >>>And I would expect that to render as such:
Paragraph 1
Paragraph 2
Paragraph 3
The original text is formatted as a code block for some reason. Depending on what lemmy front-end (specifically which Markdown renderer) you use, code blocks can be rendered with syntax highlighting as if they were programming language snippets. Check the source of this comment to see the difference:
This code block uses the default syntax highlighting on the Lemmy web front-end. It might look different in other clients.This code block doesn't use highlighting at all because it is defined as a "text" code block.I don’t see anything, I guess the app you’re using is doing it
Not certain what you mean by “colour coding certain words and phrases”, the gitlabs bullet points translated into “code” in lemmy markdown when I copy pasted the linked comment. I decided that it was good enough and didn’t bother editing.
The good thing about code is that it won’t linebreak unexpectedly and allow you to format a code snippet correctly when needed.
#Code snippet with four leading spacesUsing Voyager App on Android, it appears that the syntax highlighting defaults to SQL for code blocks without a specified language?
Strange




