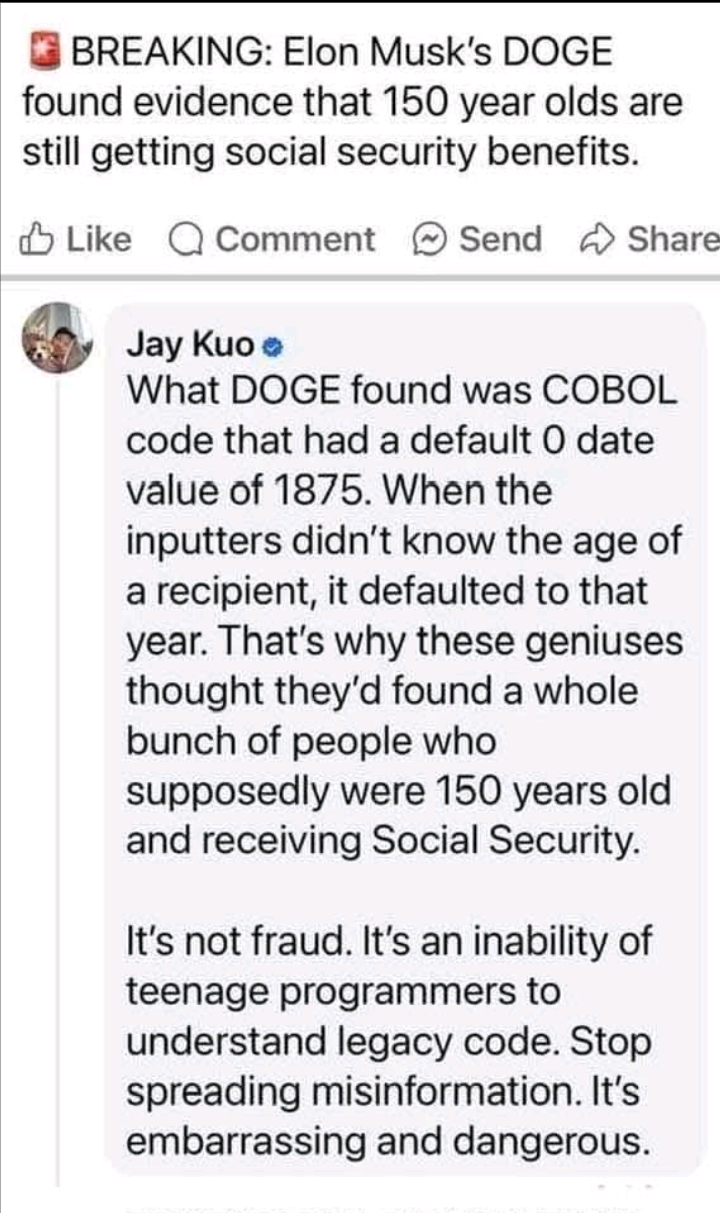
Also a lot of people between 110 and 150, so I’m sure there is a larger answer.
However, Social Security cuts off at 115, and they supposedly found like 10 million people older than that. Considering there are only ~50m people on Social Security, and the database they were searching wasn’t even about current recipients, most people would conclude that there is likely an error in data, rather than immediately jump to fraud. Of course, ketamine is a hell of a drug and Elon is not most people.
the database doesn’t have to necessarily be accurate if there’s other checks - a flag for test data, a system that checks the person is real against another database before dispersing funds etc
A minor grammar point: in this context, the word is actually “disbursing,” from the same root as “bursar,” a job title you may have encountered in school administrations. “Disbursing” means “paying out from a fund.” “Dispersing” means “scattering” or “causing to dissipate.” So the old system was disbursing funds. The new system will be dispersing funds.
Fixing an archival dataset that doesn’t even pertain to people actively receiving benefits is so far down the list of priorities as to be a criminal misuse if resources.
Someone with the skills and knowledge to clean up 150-year old typographical errors in one particular table in the Social Security database system would probably provide more benefit to the taxpayers covering their salary by doing some other task.
It might be better to move to a new database at this point rather than trying to fix the existing one. It won’t give immediate benefits but could be helpful down the line.
I am hoping California ditches SSN and other identifiers from the US Treasury. That information is no longer safe, so we need a fresh database that is secure from DOGE fuckery, among many other hostile actors.
How would you clean up that data? If they didn’t have the correct data in the first place, where do you expect to find it decades later?
Sometime real life is just bad data and that’s not necessarily a problem. All of the business logic and agency process around not spending money for those situations is probably one of the difficult areas blocking modernization or shrinkage. Bad data is reality. How you handle it shows how experienced you are

{kind=link}
Also a lot of people between 110 and 150, so I’m sure there is a larger answer.
However, Social Security cuts off at 115, and they supposedly found like 10 million people older than that. Considering there are only ~50m people on Social Security, and the database they were searching wasn’t even about current recipients, most people would conclude that there is likely an error in data, rather than immediately jump to fraud. Of course, ketamine is a hell of a drug and Elon is not most people.
It’s definitely still concerning if the database has a large number of errors. But systematic fraud would be much worse ofc.
the database doesn’t have to necessarily be accurate if there’s other checks - a flag for test data, a system that checks the person is real against another database before dispersing funds etc
A minor grammar point: in this context, the word is actually “disbursing,” from the same root as “bursar,” a job title you may have encountered in school administrations. “Disbursing” means “paying out from a fund.” “Dispersing” means “scattering” or “causing to dissipate.” So the old system was disbursing funds. The new system will be dispersing funds.
It’s really funny to me that everyone thinks every database is always 100% correct. What a magical world it would be!
That’s true. Would be better if it was though.
Fixing an archival dataset that doesn’t even pertain to people actively receiving benefits is so far down the list of priorities as to be a criminal misuse if resources.
Someone with the skills and knowledge to clean up 150-year old typographical errors in one particular table in the Social Security database system would probably provide more benefit to the taxpayers covering their salary by doing some other task.
It might be better to move to a new database at this point rather than trying to fix the existing one. It won’t give immediate benefits but could be helpful down the line.
Or it could cost a fortune and fuck a lot of other processes up.
That’s true
I am hoping California ditches SSN and other identifiers from the US Treasury. That information is no longer safe, so we need a fresh database that is secure from DOGE fuckery, among many other hostile actors.
How would you clean up that data? If they didn’t have the correct data in the first place, where do you expect to find it decades later?
Sometime real life is just bad data and that’s not necessarily a problem. All of the business logic and agency process around not spending money for those situations is probably one of the difficult areas blocking modernization or shrinkage. Bad data is reality. How you handle it shows how experienced you are
Lol why bring drugs into this? Specifically ketamine?
Because Musk is pretty open about his ketamine abuse